TidalSim: A Unified Microarchitectural Simulation Framework
To Identify and Leverage Unique Aspects of Workloads on Heterogeneous SoCs for Performance Estimation and Verification
Vighnesh Iyer
Qualifying Exam Presentation
Wednesday, January 17th, 2024
Talk Outline
- Why: What is the problem I'm solving?
- What: What is the thing I want to build?
- Prior work + what's new about my proposal?
- How (pt 1): A prototype implementation of my proposal
- Case studies / applications: Using TidalSim for performance optimization and verification
- How (pt 2): New contributions to sampled simulation methodology
- Thesis outline
1. Why: What Is the Problem?
The New-Era of Domain-Specialized Heterogeneous SoCs
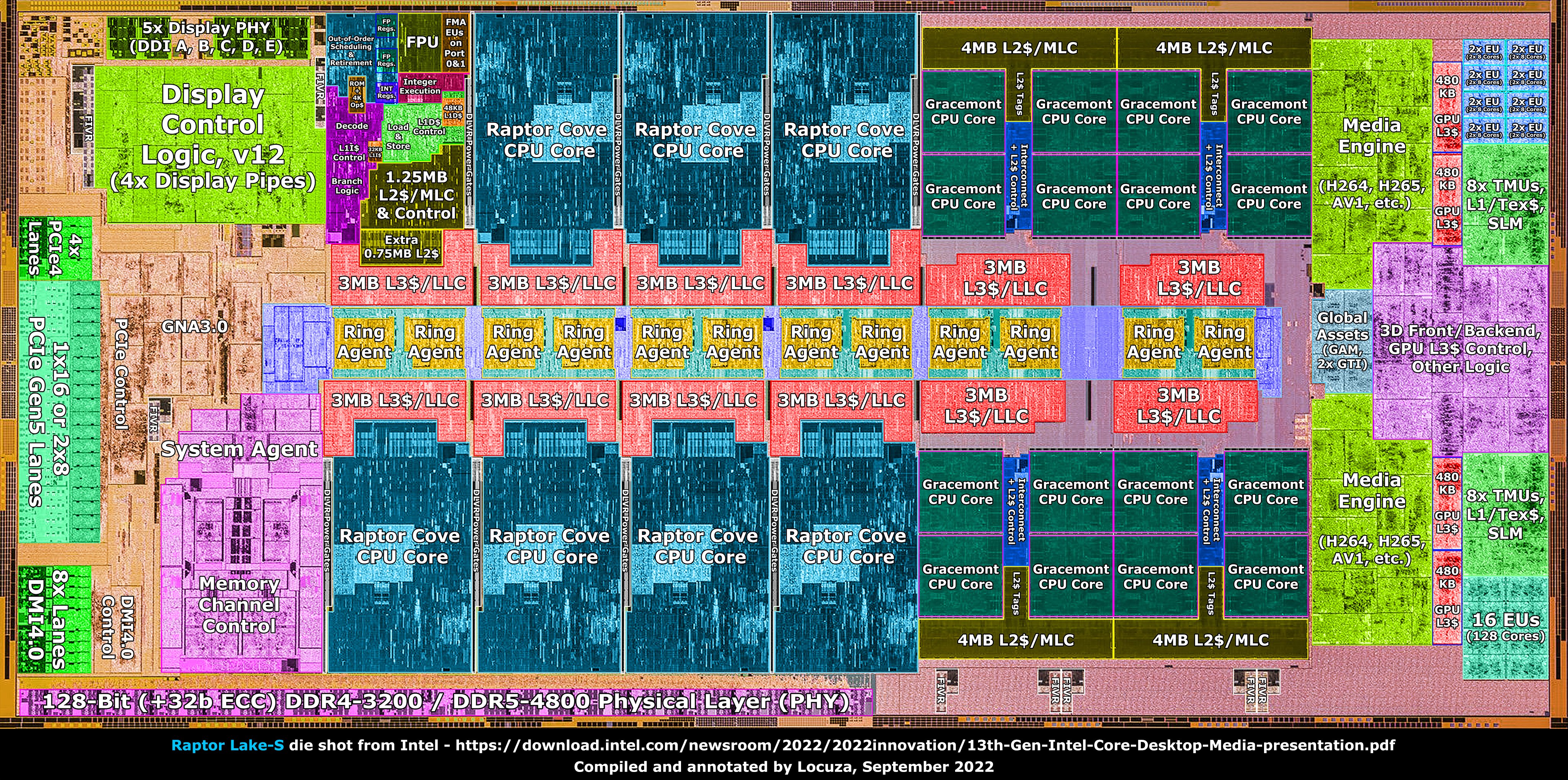
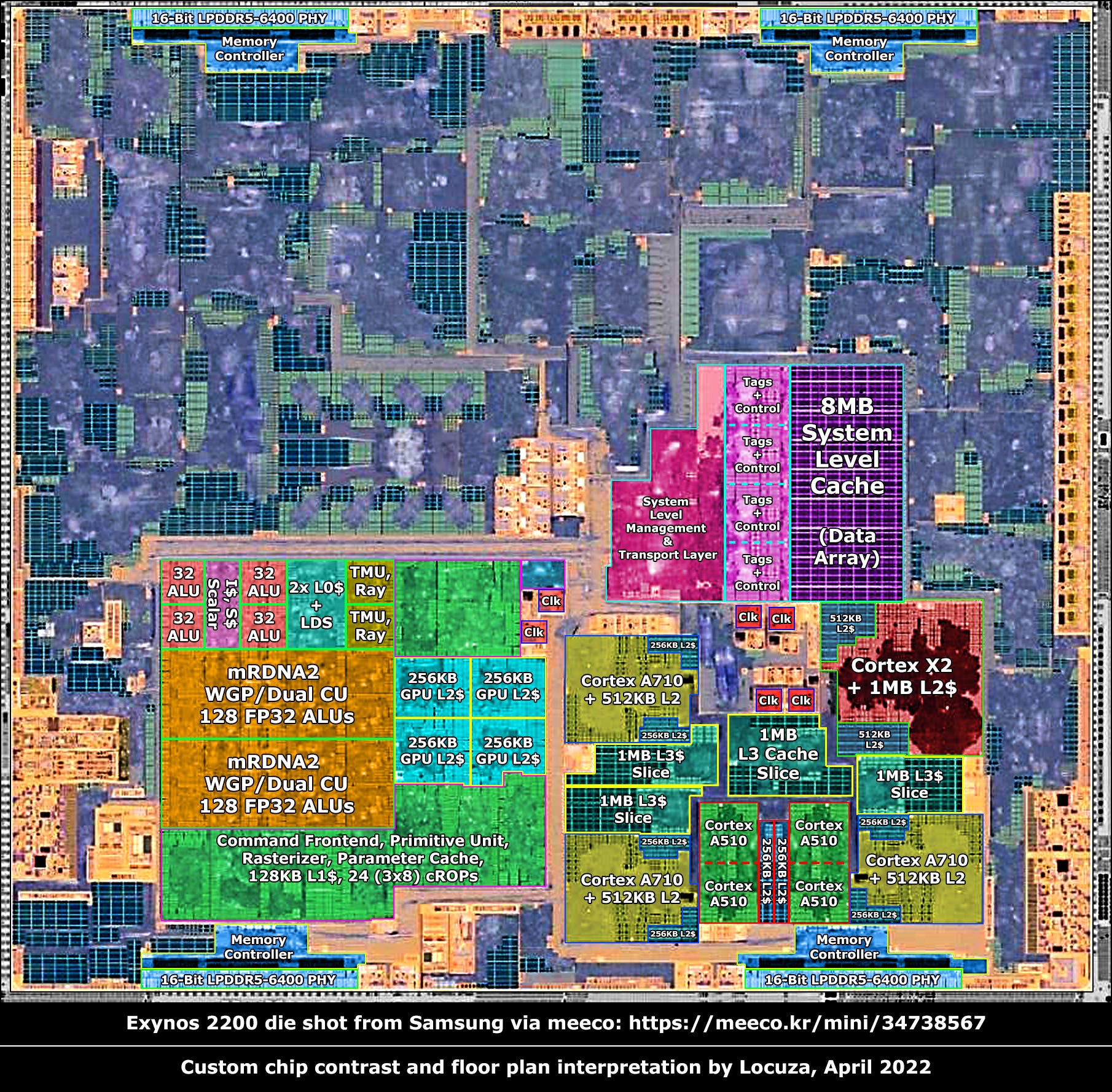
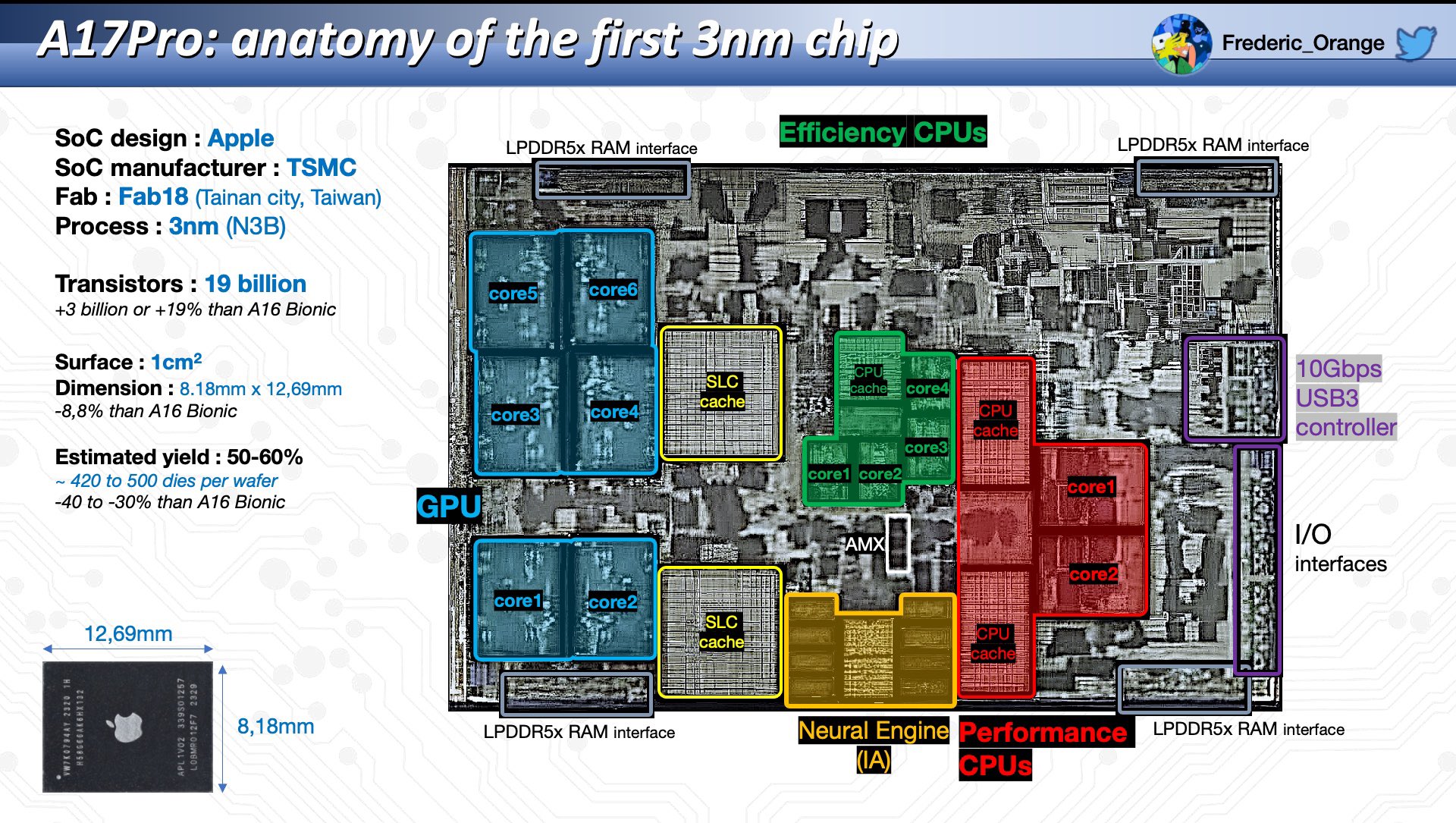
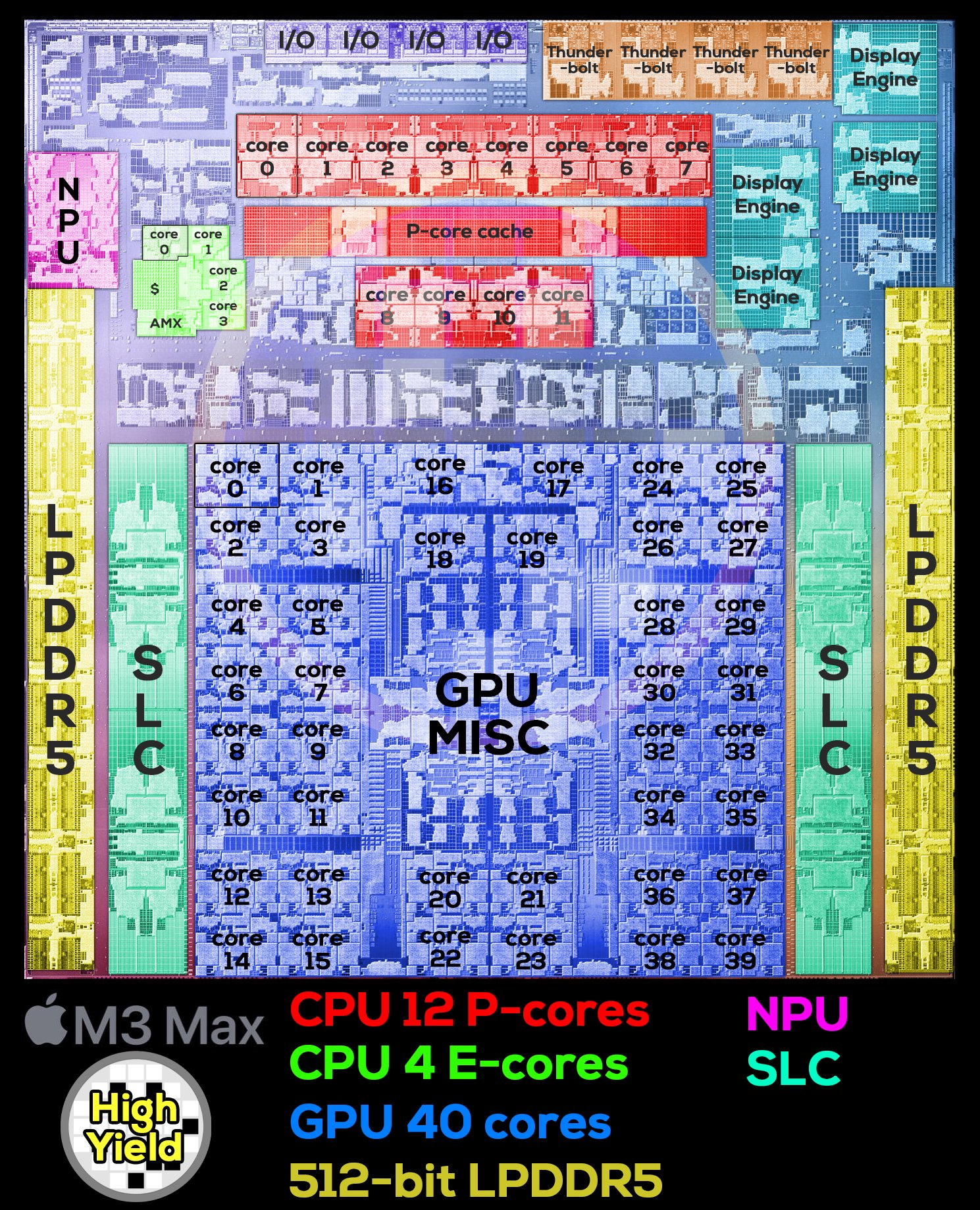
- Two trends in SoC design:
- Heterogeneous cores targeting different power/perf curves + workloads
- Domain-specific accelerators
- Need a pre-silicon evaluation strategy for rapid, PPA optimal design of these units
- Limited time per design cycle → limited time per evaluation
- More evaluations = more opportunities for optimization
The Microarchitectural Iteration Loop (Industry)



Industry needs a methodology for rapid RTL performance validation that can be used in the RTL design cycle.
The Microarchitectural Iteration Loop (Academia)

Academia needs a methodology for rapid RTL evaluation as a part of an RTL-first evaluation strategy
The Microarchitectural Iteration Loop (Startup)


Chip startups need a methodology for low-cost and rapid RTL evaluation to enable high productivity and confidence
Limitations of Existing Evaluators
- ISA simulation: no accuracy
- Trace/Cycle uArch simulation: low accuracy
- RTL simulation: low throughput
- FPGA prototyping: high startup latency
- HW emulators: high cost
We will propose a simulation methodology that can deliver on all axes (accuracy, throughput, startup latency, cost) and is useful for industry, academics, and startups.
Backup Slides
The End of "Free" Technology Scaling
Moore's Law: transistor counts double while cost/transistor halves every 2 years
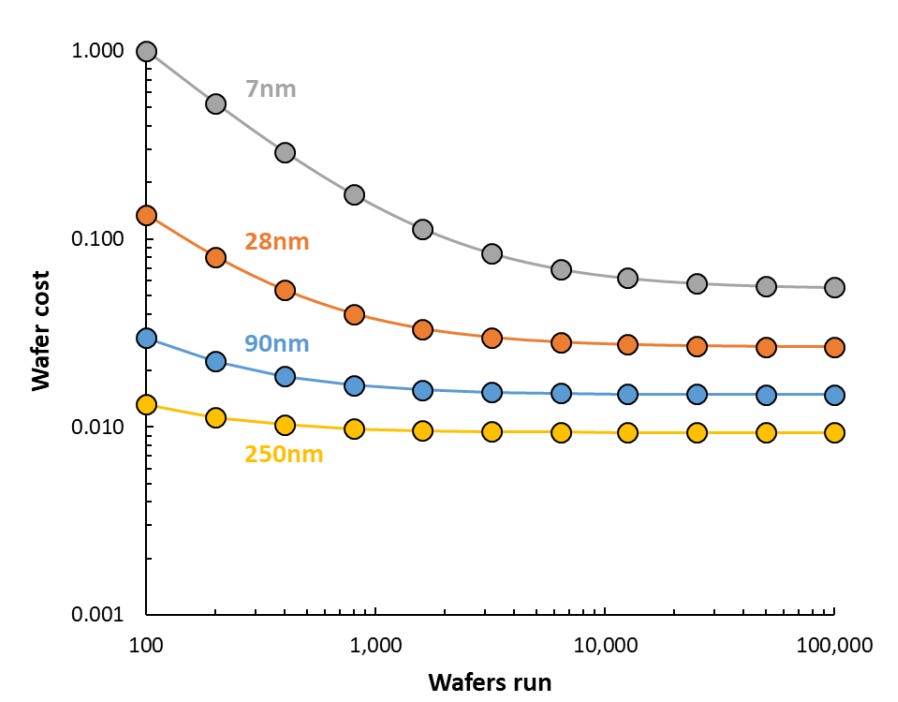
- Per-wafer and per-transistor costs continue to grow with process scaling[1, 2] unless heavily amortized
→ Transistors are no longer free
Stagnation of Single Thread Performance
Dennard Scaling: power density is constant with technology scaling
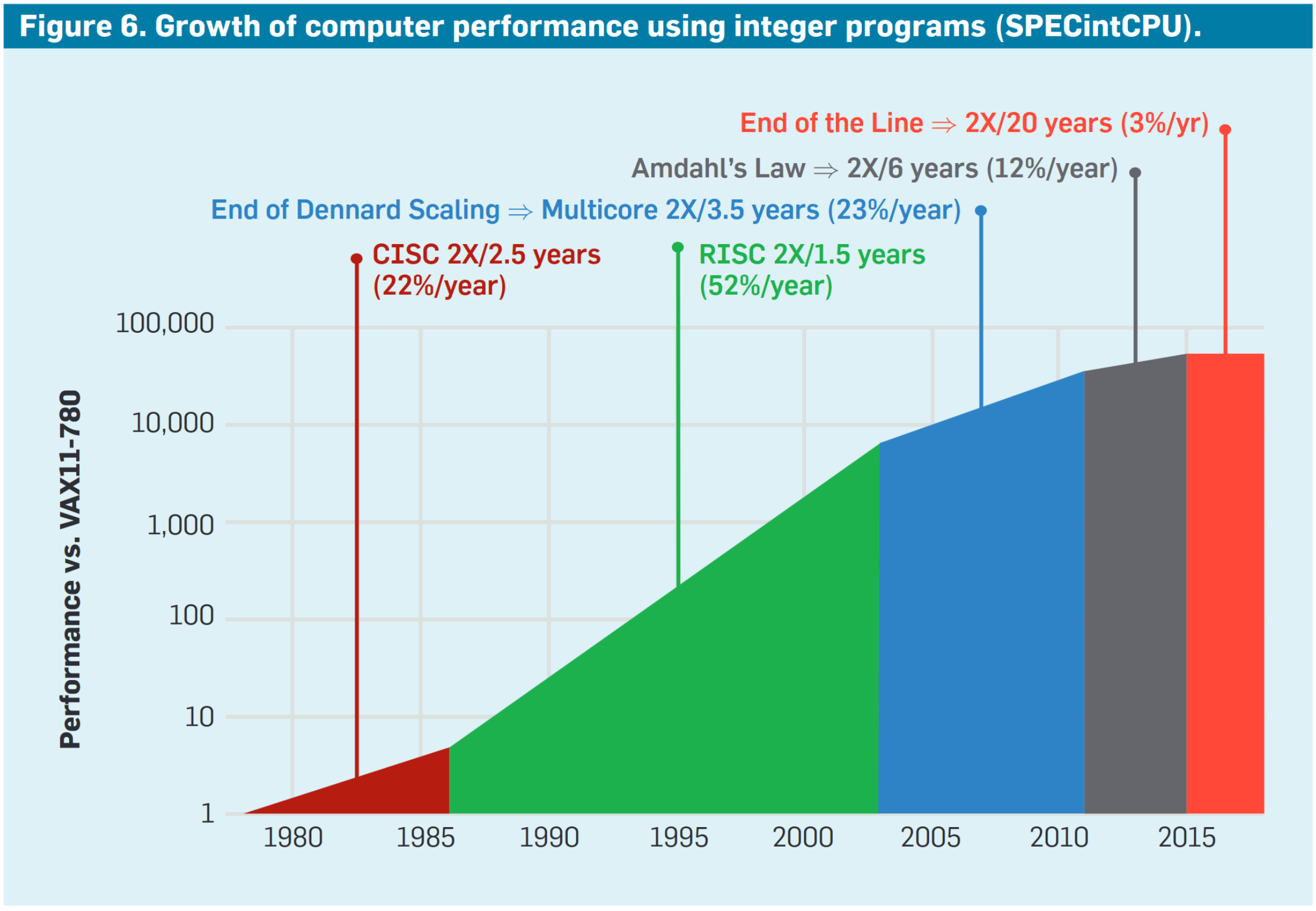
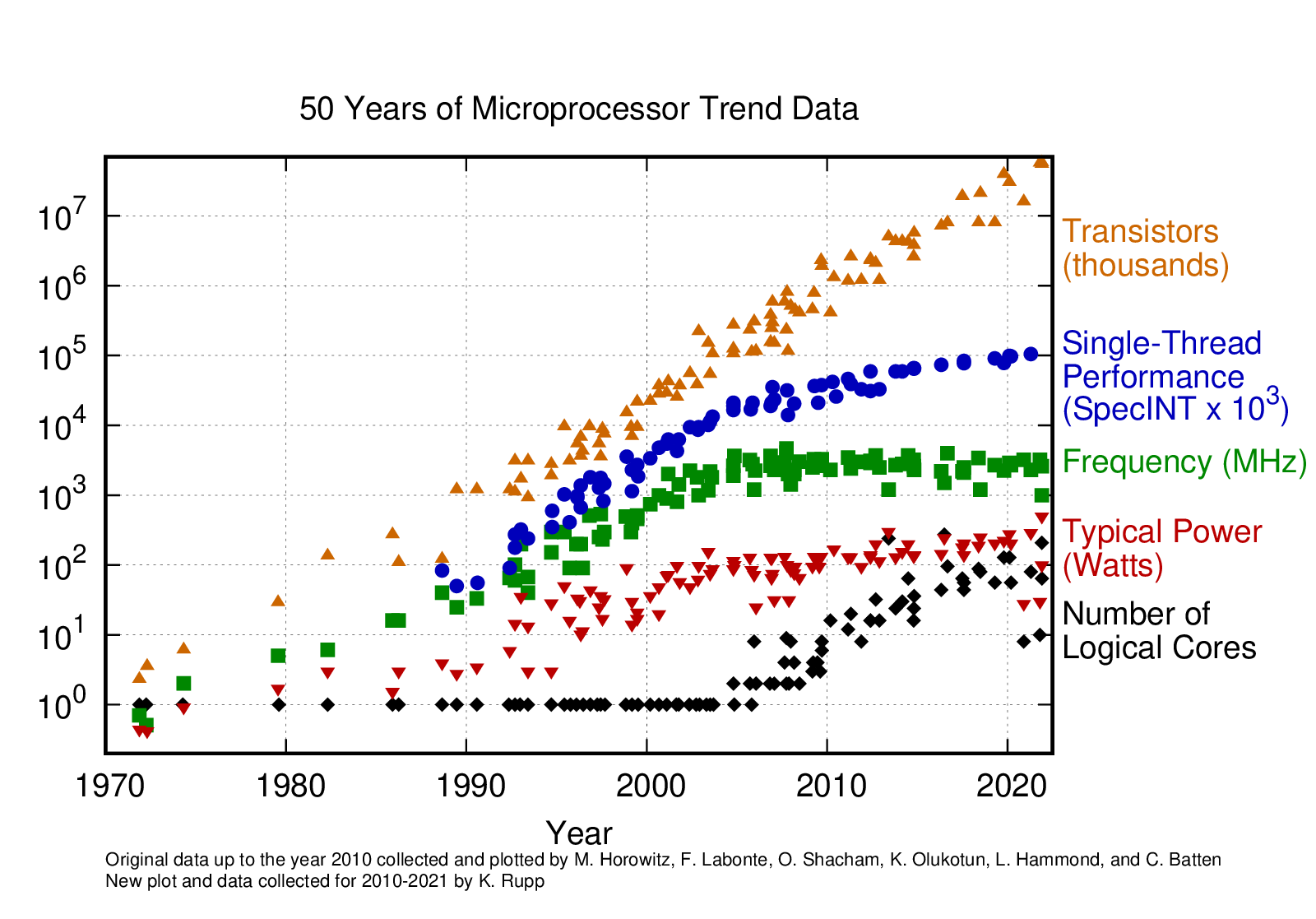
- General-purpose single-thread performance has stagnated[1,2]
→ Can't rely on technology scaling for gains in performance
Trends in SoCs
End of Moore's Law
→ $/transistor not falling
→ Transistors are no longer free
→ Need aggressive PPA optimization
End of Dennard Scaling
→ Power density increasing
→ GPP performance stagnating
→ Need domain-specialization to not stagnate
Motivates two trends in SoC design
- Heterogeneous cores
- Cores targeting different power/performance curves
- Domain-specific cores
- Core-coupled accelerators (ISA extensions)
- Domain-specific accelerators
Specialized Core Microarchitectures

- Different CPUs in the same SoC aren't just variants of the same underlying microarchitecture
- The broad categories of microarchitectural iteration
- Creating a new structure (vector unit, prefetcher, new type of branch predictor)
- Optimizing an existing structure (ROB dispatch latency, new forwarding path)
- Tuning hardware parameters (cache hierarchy and sizing, LSU queue sizing)
- Must evaluate PPA tradeoffs of each modification on specific workloads
Microarchitecture Design Challenges
- We want optimal designs for heterogeneous, domain-specialized, workload-tuned SoCs
- Limited time to iterate on microarchitecture and optimize PPA on real workloads
- Time per evaluation (microarchitectural iteration loop) limits number of evaluations
More evaluations = more opportunities for optimization
2. What: Our Vision for TidalSim
What if we had a magic box that:
- Is fast enough to run real workloads
- Is accurate enough to use confidently for microarchitectural DSE
- Has low latency to not bottleneck the hardware iteration loop
- Can produce RTL-level collateral for performance or functional verification
- Can run real workloads by identifying unique aspects of the program automatically
What: TidalSim

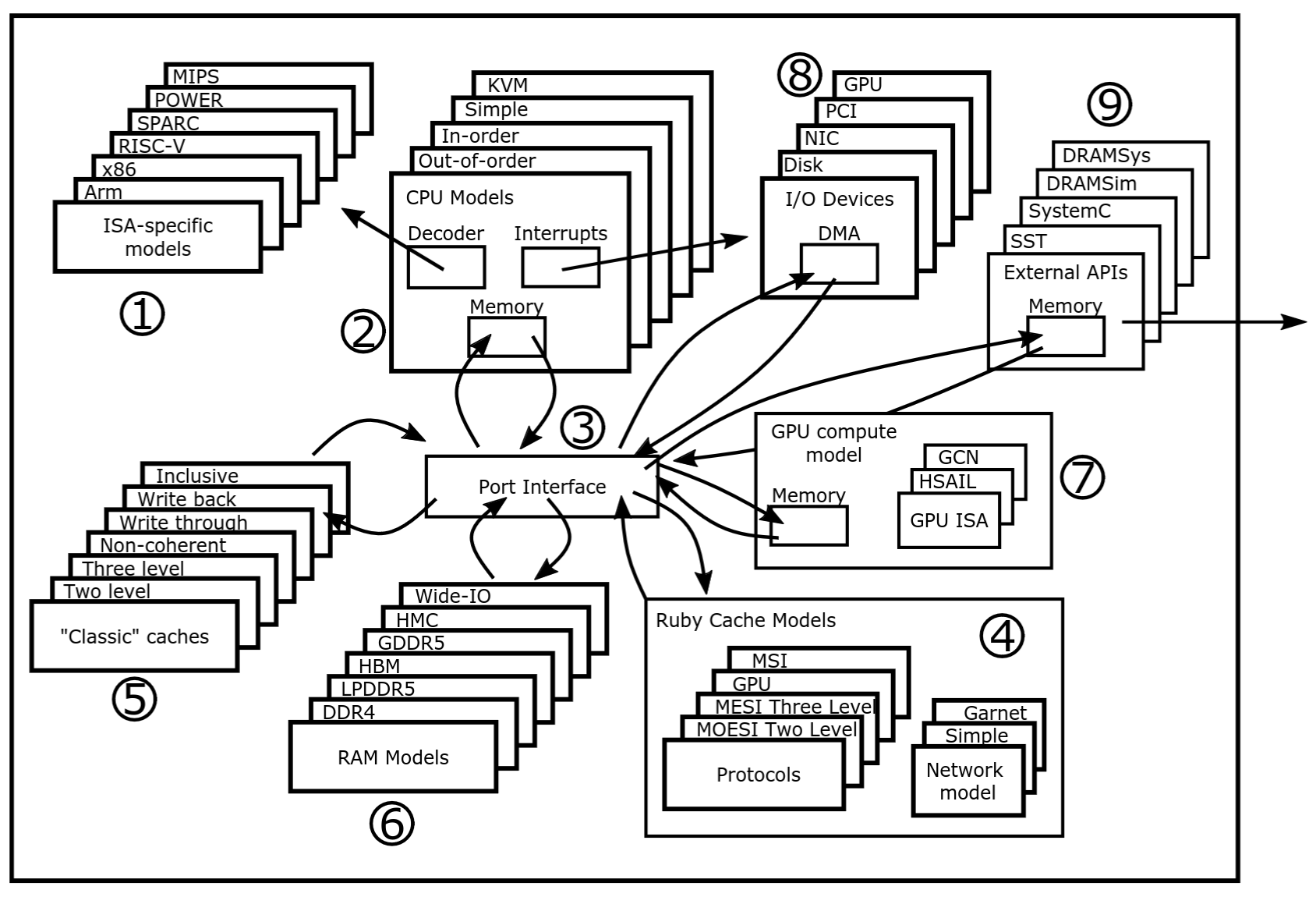
TidalSim Components

TidalSim is not a simulator. It is a simulation methodology that combines the strengths of architectural simulators, uArch models, and RTL simulators.
TidalSim Execution

What Does TidalSim Enable?
Industry
Industry

Academia
Academia

Startup / Lean Team
Startup / Lean Team

TidalSim enables new design methodologies for industry, academia, and lean chip design teams.
Scope of Thesis
- Implementation of TidalSim
- Evaluation of TidalSim for performance estimation on realistic and large workloads
- Embench, SPEC, HyperProtoBench, HyperCompressBench
- Case studies for hardware DSE and coverpoint synthesis
3. Background and Prior Work
- An overview of simulation broadly
- Abstractions used in hardware modeling
- Comparison of existing pre-silicon simulation techniques
- The limitations of microarchitectural simulators
- Sampled simulation
- SimPoint: Representative sampling + phase behavior of programs
- SMARTs: Random sampling
- Functional warmup techniques
- Why RTL-level sampled simulation?
Hardware Abstractions
- Architectural (functional) models
- Emulate an ISA; they only model architectural state, not uArch state
- Examples: spike (RISC-V), qemu (multiple ISAs)
- Microarchitectural models ("rough") with approximate state and timing
- Inputs: High-level microarchitectural description, workload characteristics
- Outputs: Performance estimate (e.g. aggregate IPC)
- Example: McPAT
- Microarchitectural models ("detailed") with more refined state and timing
- Inputs: Detailed microarchitectural description, ELF binary
- Outputs: Detailed pipeline execution trace + low-level performance metrics
- Examples: gem5, ZSim, SST, MARSSx85, Sniper, ESESC
- Register-transfer level (RTL) models with full fidelity state and timing
- Examples: Verilog, Chisel
Each abstraction makes an accuracy / latency / throughput tradeoff.
Simulator Metrics
Simulation techniques span the gamut on various axes. Each simulation technique assumes a particular hardware abstraction.
- Throughput
- How many instructions can be simulated per real second? (MIPS = millions of instructions per second)
- Accuracy
- Do the output metrics of the simulator match those of the modeled SoC in its real environment?
- Startup latency
- How long does it take from the moment the simulator's parameters/inputs are modified to when the first instruction is executed?
- Cost
- What hardware platform does the simulator run on?
- How much does it cost to run a simulation?
Existing Hardware Simulation Techniques
| Examples | Throughput | Latency | Accuracy | Cost | |
|---|---|---|---|---|---|
| Architectural Simulators | spike, qemu | 10-100+ MIPS | <1 second | None | Minimal |
| μArch Simulators | gem5, Sniper, ZSim, SST | 100 KIPS (gem5) - 100 MIPS (Sniper) | <1 minute | 10-50% IPC error | Minimal |
| RTL Simulators | Verilator, VCS, Xcelium | 1-10 KIPS | 2-10 minutes | Cycle-exact | Minimal |
| FPGA-Based Emulators | Firesim | ≈ 10 MIPS | 2-6 hours | Cycle-exact | $10k+ |
| ASIC-Based Emulators | Palladium, Veloce | ≈ 0.5-10 MIPS | <1 hour | Cycle-exact | $10M+ |
| Multi-level Sampled Simulation | TidalSim | 10+ MIPS | <1 minute | <1% IPC error | Minimal |
TidalSim combines the strengths of each technique to produce a meta-simulator that achieves high throughput, low latency, high accuracy, and low cost.
Accuracy of Microarchitectural Simulators
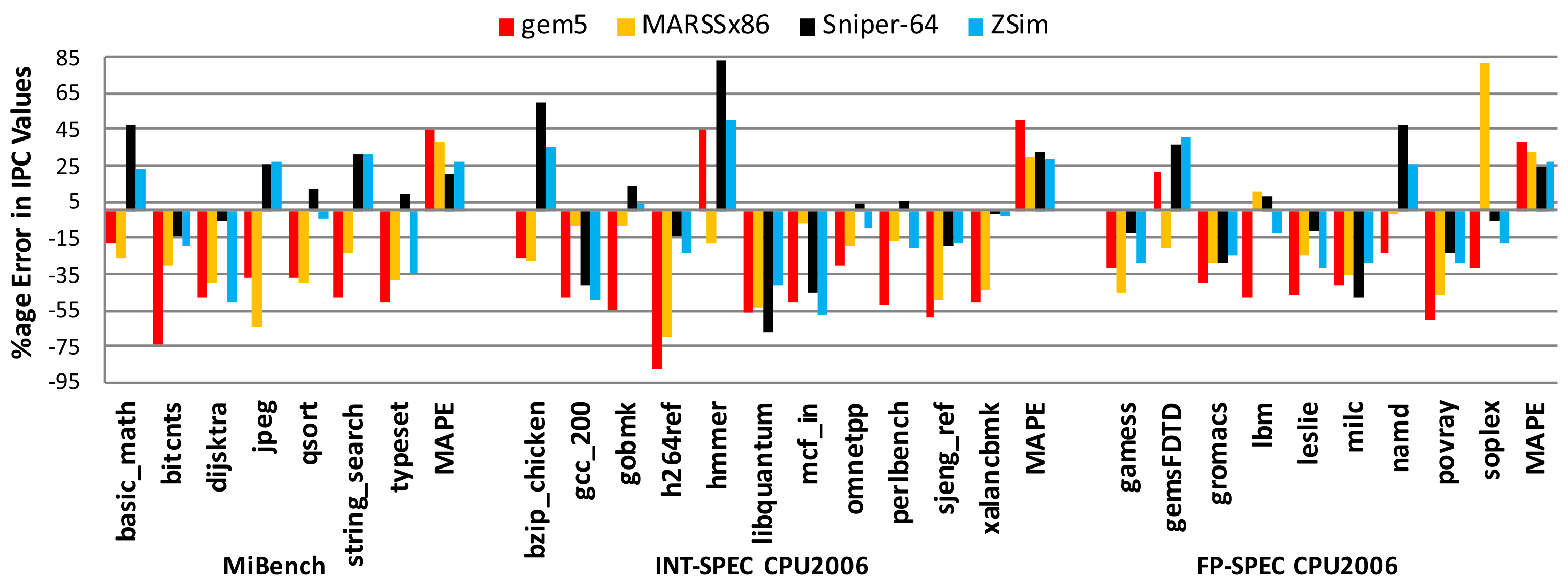
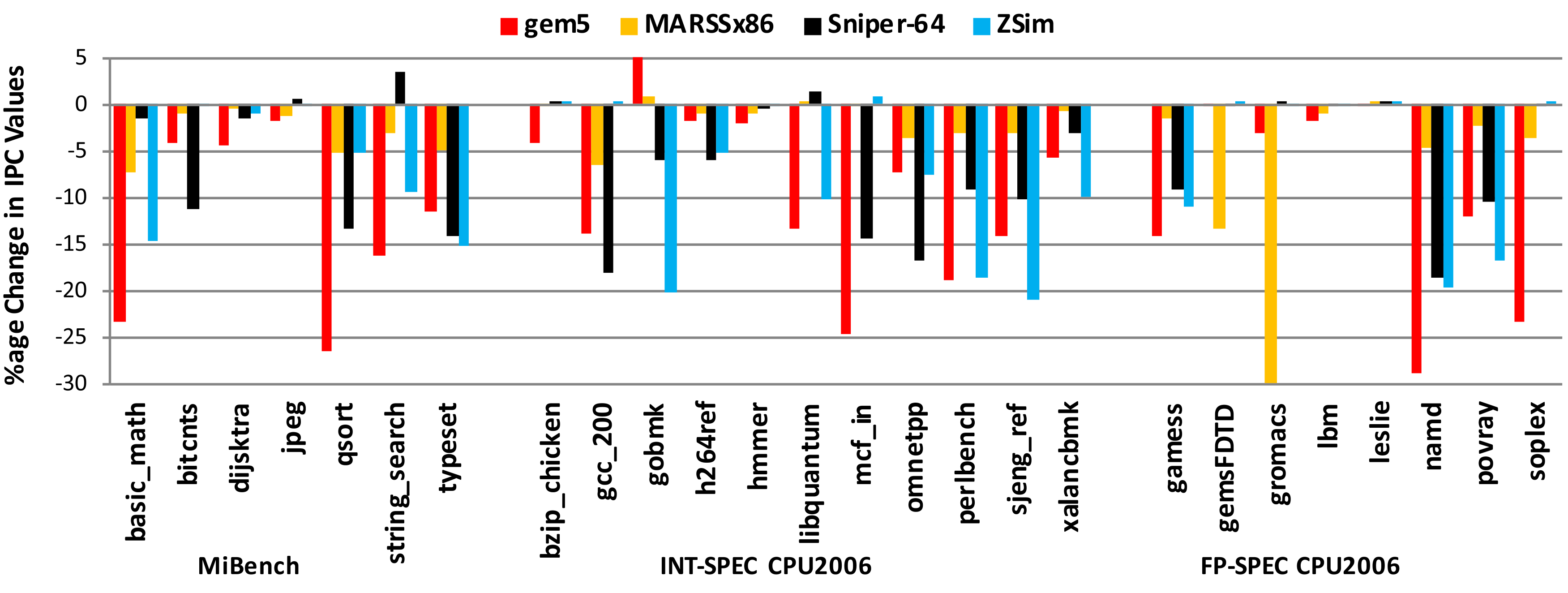
Trends aren't enough[2]. Note the sensitivity differences - gradients are critical!
uArch simulators are not accurate enough for microarchitectural evaluation.
[1]: Akram, A. and Sawalha, L., 2019. A survey of computer architecture simulation techniques and tools. IEEE Access
[2]: Nowatzki, T., Menon, J., Ho, C.H. and Sankaralingam, K., 2015. Architectural simulators considered harmful. Micro.
Sampled Simulation
Instead of running the entire program in uArch simulation, run the entire program in functional simulation and only run samples in uArch simulation
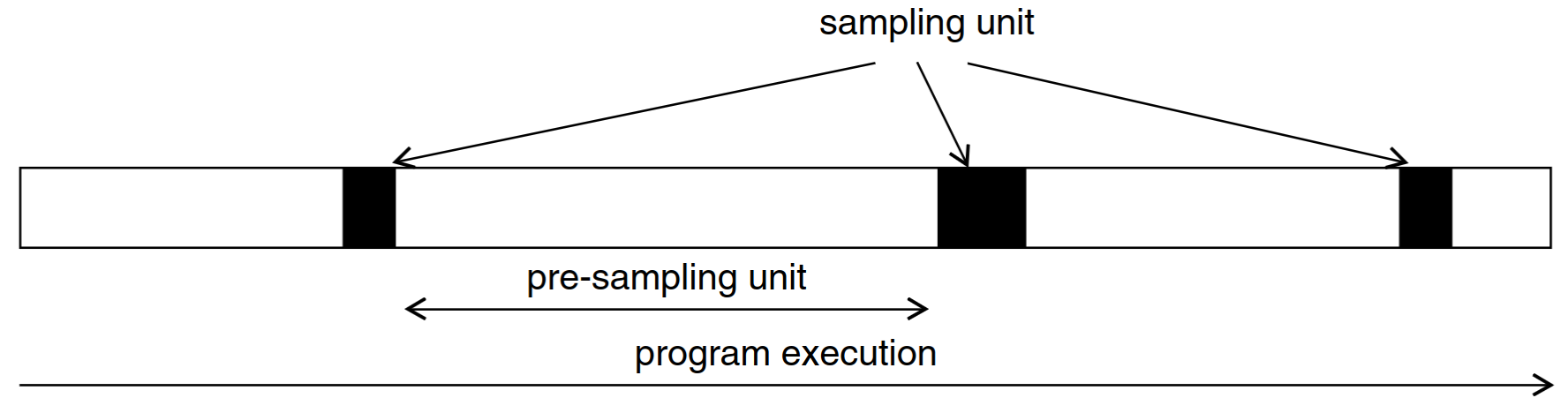
The full workload is represented by a selection of sampling units.
- How should sampling units be selected?
- How can we accurately estimate the performance of a sampling unit?
- How can we estimate errors when extrapolating from sampling units?
Existing Sampling Techniques
SimPoint

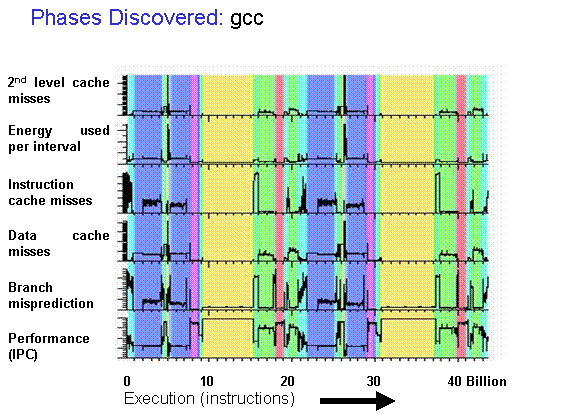
- Program execution traces aren’t random
- They execute the same code again-and-again
- Workload execution traces can be split into phases that exhibit similar μArch behavior
- SimPoint-style representative sampling
- Compute an embedding for each program interval (e.g. blocks of 100M instructions)
- Cluster interval embeddings using k-means
- Choose representative intervals from each cluster as sampling units
SMARTS

- Rigorous statistical sampling enables computation of confidence bounds
- Use random sampling on a full execution trace to derive a population sample
- Central limit theorem provides confidence bounds
- SMARTS-style random sampling
- Pick a large number of samples to take before program execution
- If the sample variance is too high after simulation, then collect more sampling units
- Use CLT to derive a confidence bound for the aggregate performance metric
Functional Warmup
The state from a sampling unit checkpoint is only architectural state. The microarchitectural state of the uArch simulator starts at the reset state!

- We need to seed long-lived uArch state at the beginning of each sampling unit
- This process is called functional warmup
Importance of Functional Warmup
Long-lived microarchitectural state (caches, branch predictors, prefetchers, TLBs) has a substantial impact on the performance of a sampling unit
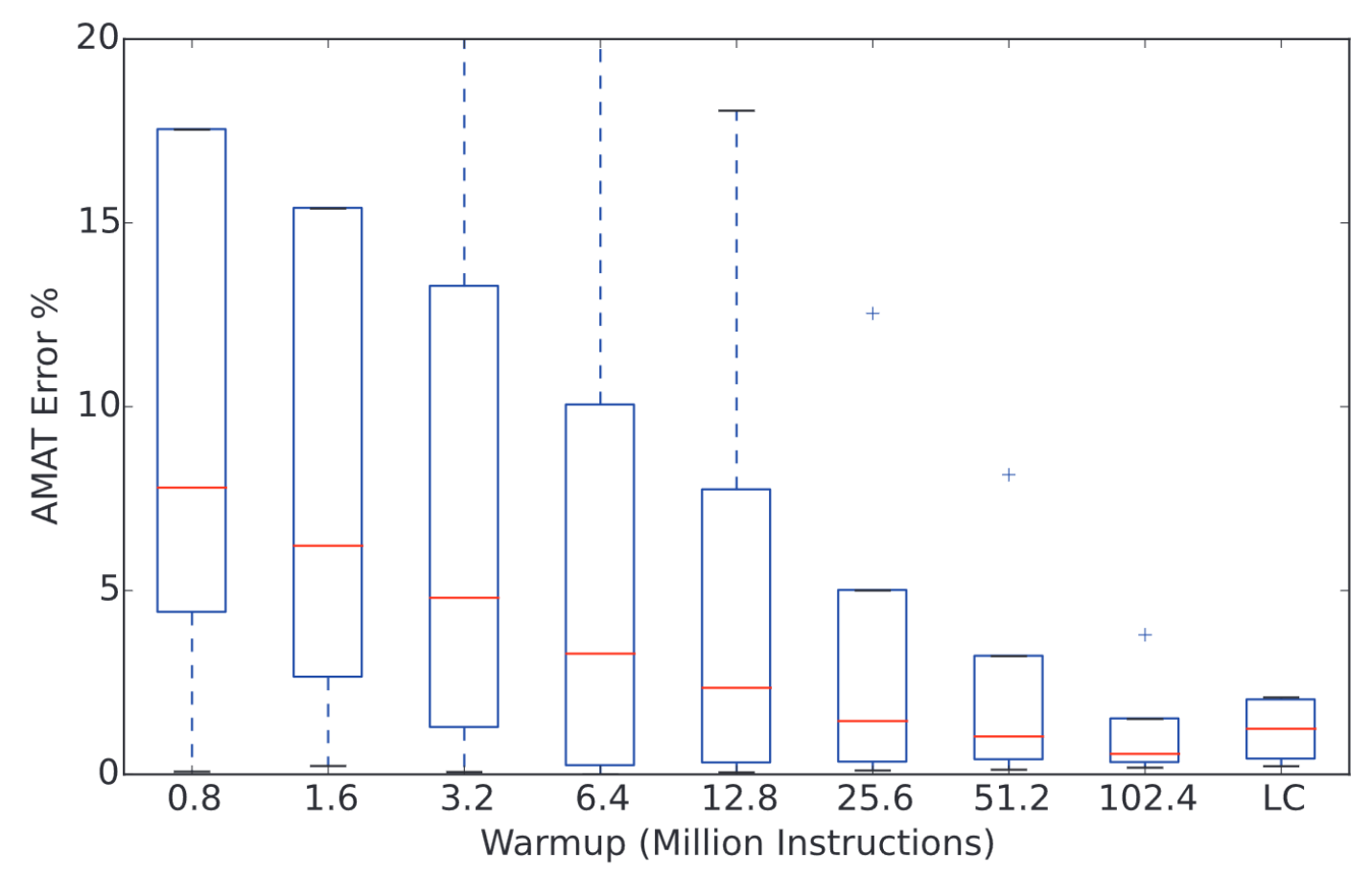

[1]: Hassani, Sina, et al. "LiveSim: Going live with microarchitecture simulation." HPCA 2016.
[2]: Eeckhout, L., 2008. Sampled processor simulation: A survey. Advances in Computers. Elsevier.
Why RTL-Level Sampled Simulation?

- Eliminate modeling errors
- Remaining errors can be handled via statistical techniques
- No need to correlate performance model and RTL
- Let the RTL serve as the source of truth
- Can produce RTL-level collateral
- Leverage for applications in verification and power modeling
This RTL-first evaluation flow is enabled by highly parameterized RTL generators and SoC design frameworks (e.g. Chipyard).
Backup Slides
A Broad View of Simulation

- Simulation is the workhorse of architecture evaluation
- Simulation inputs can have wide variation of fidelity
- Hardware spec: high-level models to detailed microarchitecture
- Workload: high-level algorithmic description to concrete binary
- The fidelity of simulation outputs tracks that of the inputs
Hardware Abstractions
There are roughly 4 levels of hardware abstractions used in architecture evaluation
- Architectural (functional) models
- "Rough" microarchitectural models with approximate state and timing
- "Detailed" microarchitectural models with more refined state and timing
- Register-transfer level (RTL) models with full fidelity state and timing
Hardware Abstractions: Architectural (Functional) Models
Functional simulators emulate an architecture and can execute workloads (e.g. ELF binaries).
They only model architectural state, defined in an ISA specification. No microarchitectural state is modeled.
- Examples
- RISC-V: spike, dromajo, Imperas riscvOVPSim
- Multi-ISA (x86, ARM, RISC-V): qemu
- Very fast (10-1000 MIPS), low startup latency (instant)
- Cannot estimate PPA
Hardware Abstractions: "Rough" uArch Models - Micro-Kernel Accelerators
- Microarchitecture is modeled with high-level blocks with a dataflow and timing relationship
- Prior Work: Aladdin[1] is a microarchitecture estimation and simulation tool for analyzing the PPA of potential accelertors for kernels written in C
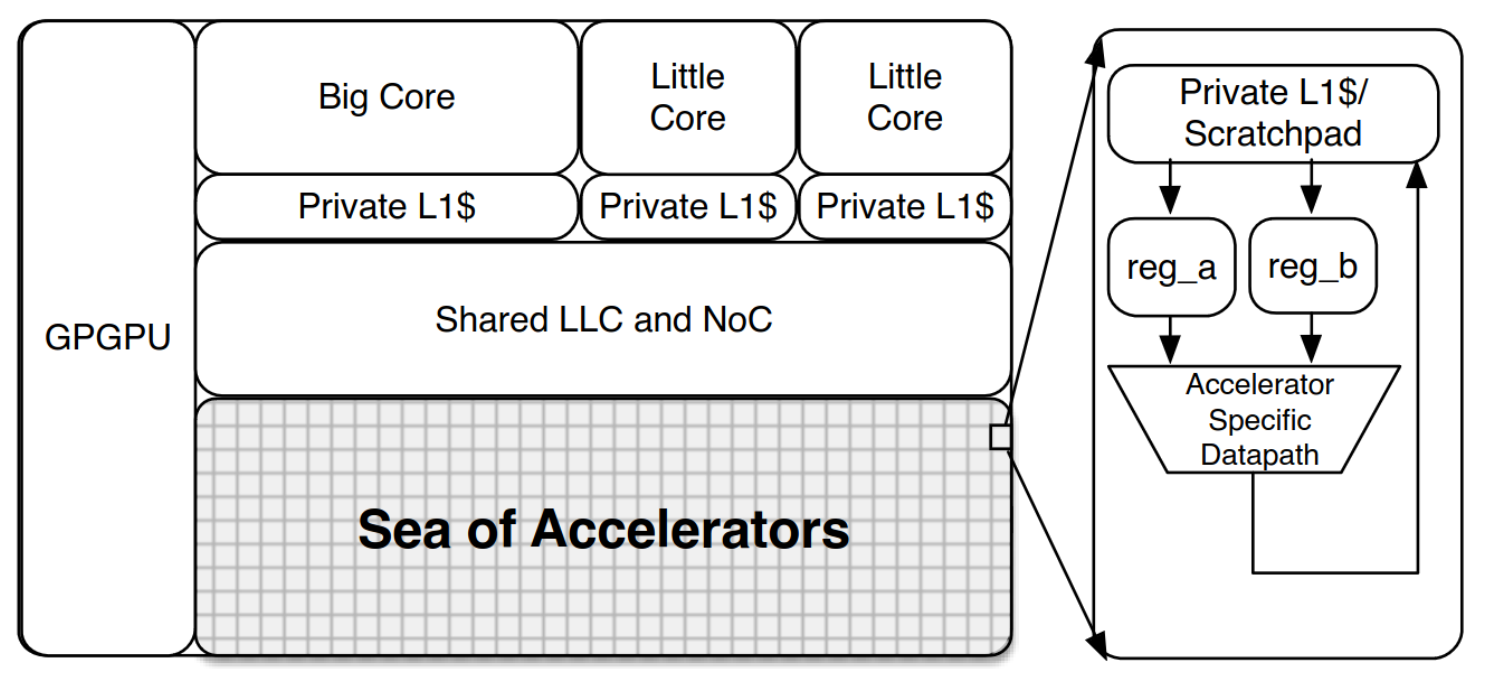
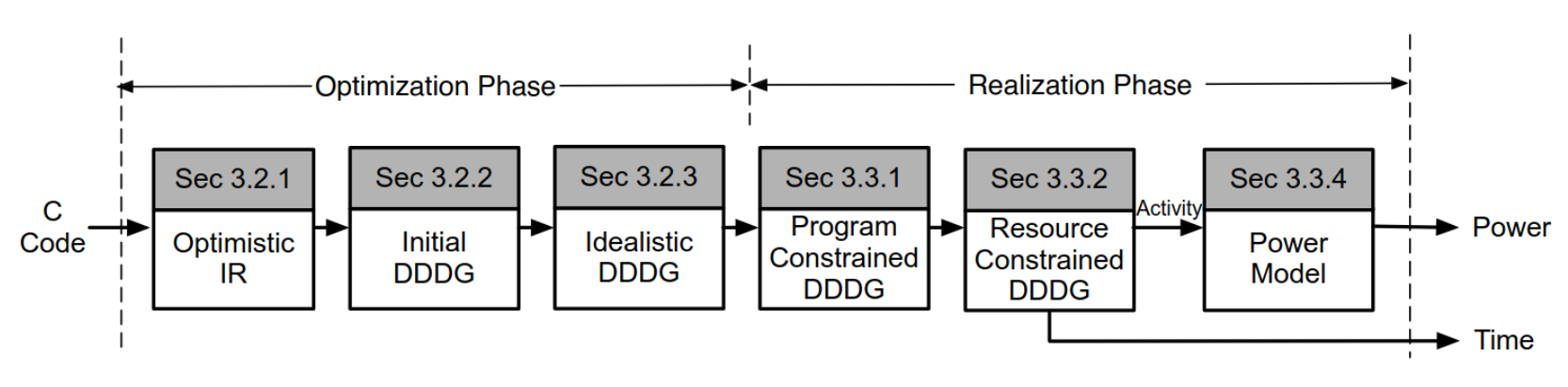
[1]: Shao, Y.S., Reagen, B., Wei, G.Y. and Brooks, D., 2014. Aladdin: A pre-rtl, power-performance accelerator simulator enabling large design space exploration of customized architectures. ACM SIGARCH.
Hardware Abstractions: "Rough" uArch Models - ML Accelerators
- Rough uArch models are used for evaluating ML accelerator architectures, dataflows, and workload mappings
- Prior Work: Timeloop[1], Accelergy[2] provides a framework for describing accelerator microarchitecture with parameterizable blocks (PEs, scratchpads), workload mappings, and simulating workloads for PPA estimates
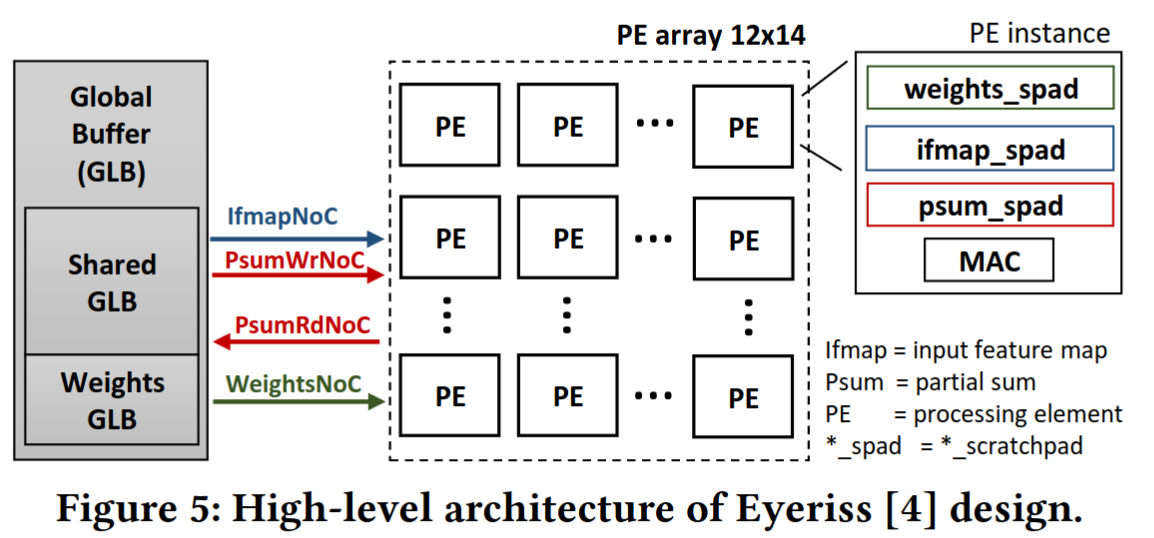


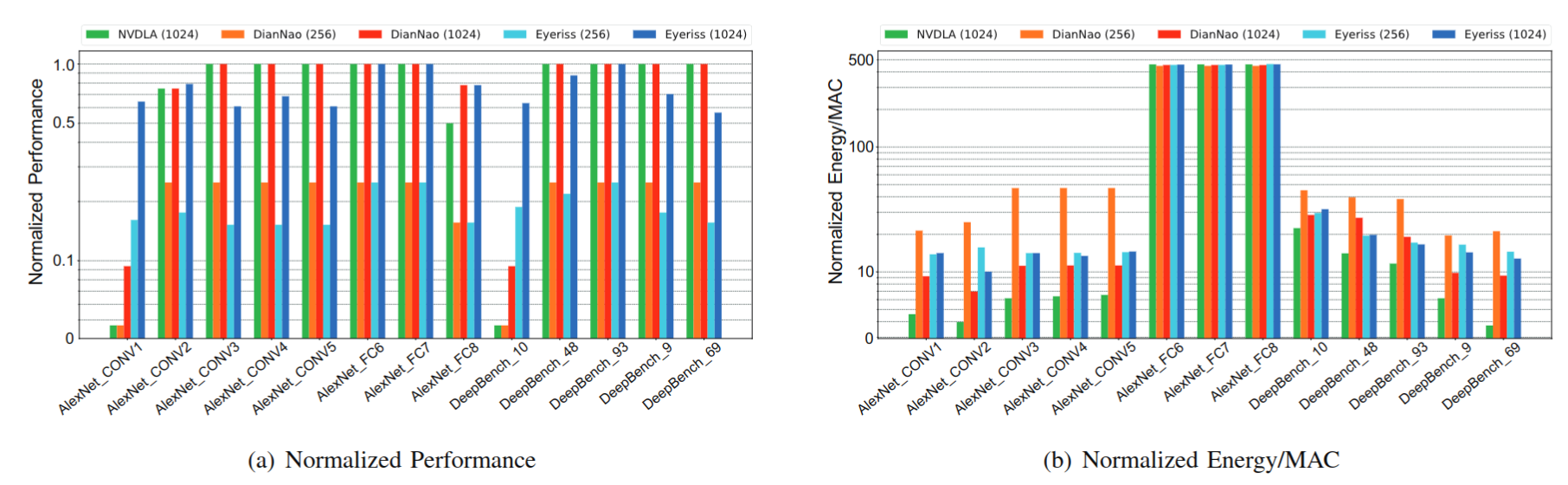
[1]: Parashar, A., et. al., 2019. Timeloop: A systematic approach to dnn accelerator evaluation. ISPASS.
[2]: Wu, Y.N., Emer, J.S. and Sze, V., 2019. Accelergy: An architecture-level energy estimation methodology for accelerator designs. ICCAD.
Hardware Abstractions: "Rough" uArch Models - Cores
- Rough uArch models are also common for evaluating core microarchitectures
- Prior Work: McPAT[1] models CPUs with a parameterizable out-of-order pipeline and uncore components coupled to a timing simulator. CACTI[2] models the PPA of SRAM-based caches and DRAM.
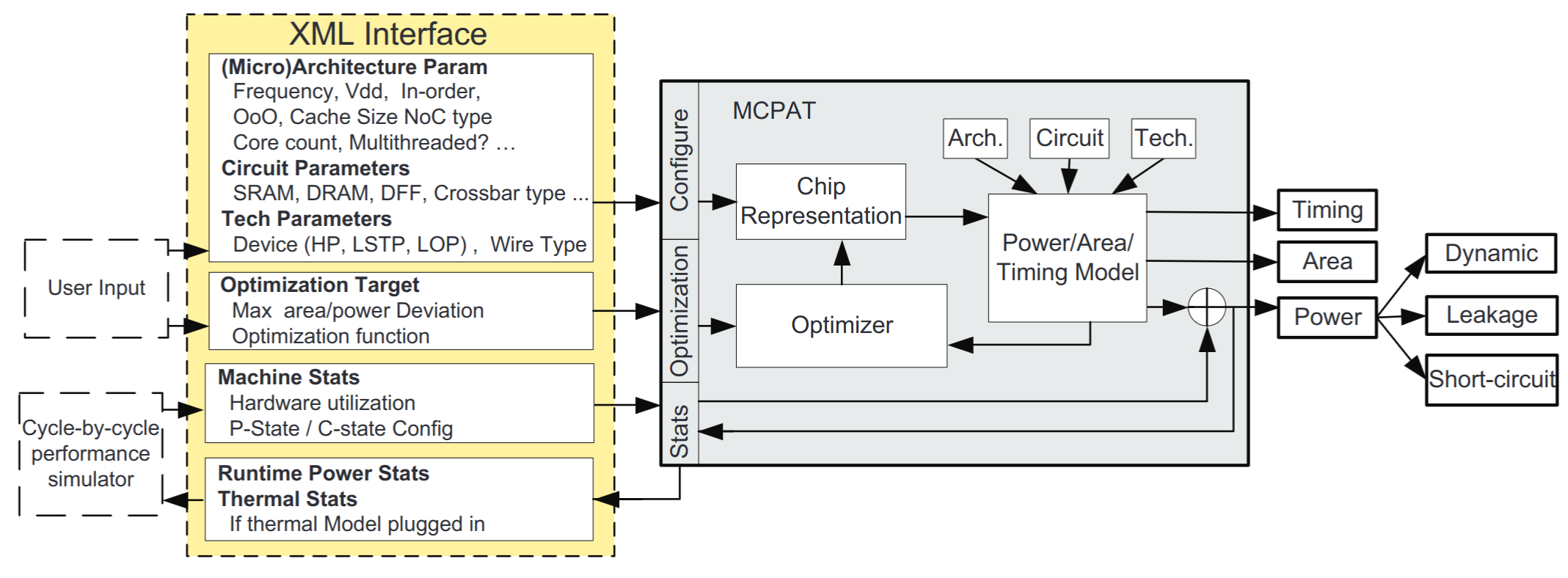
[1]: Li, S., et. al., 2009. McPAT: An integrated power, area, and timing modeling framework for multicore and manycore architectures. MICRO.
[2]: Muralimanohar, et al., 2009. CACTI 6.0: A tool to model large caches. HP laboratories.
Hardware Abstractions: "Detailed" uArch Models - Cores
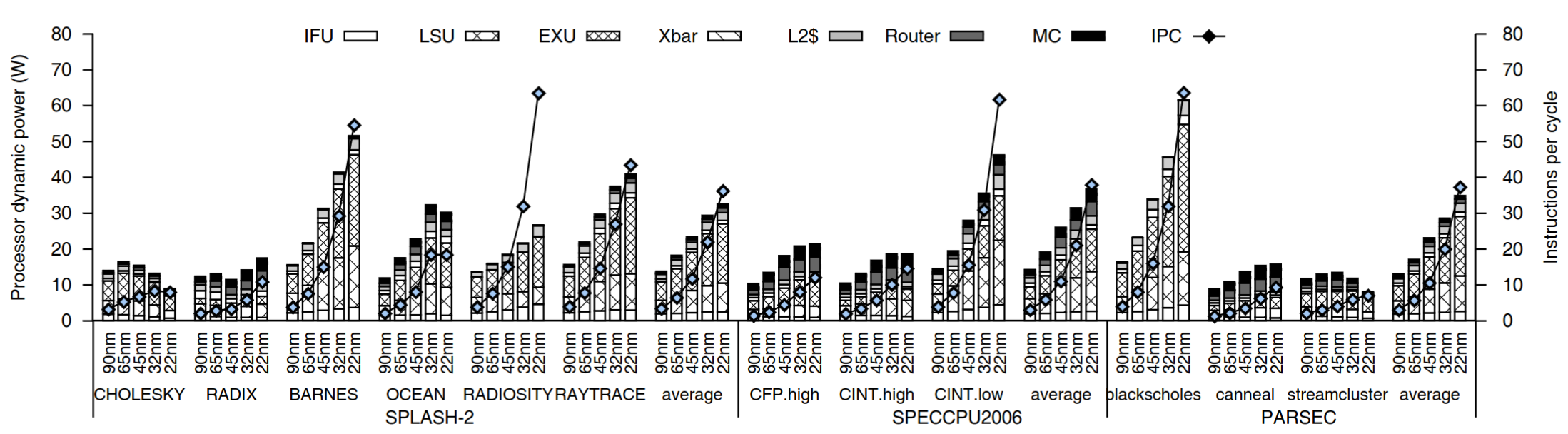
- The most popular way to evaluate core microarchitectural optimizations is with a detailed execution-driven simulator. Many microarchitectural states are modeled.
- Prior Work: gem5, ZSim, SST, MARSSx86, Sniper, ESESC. These simulators model the core pipeline and uncore components with cycle-level time-granularity.
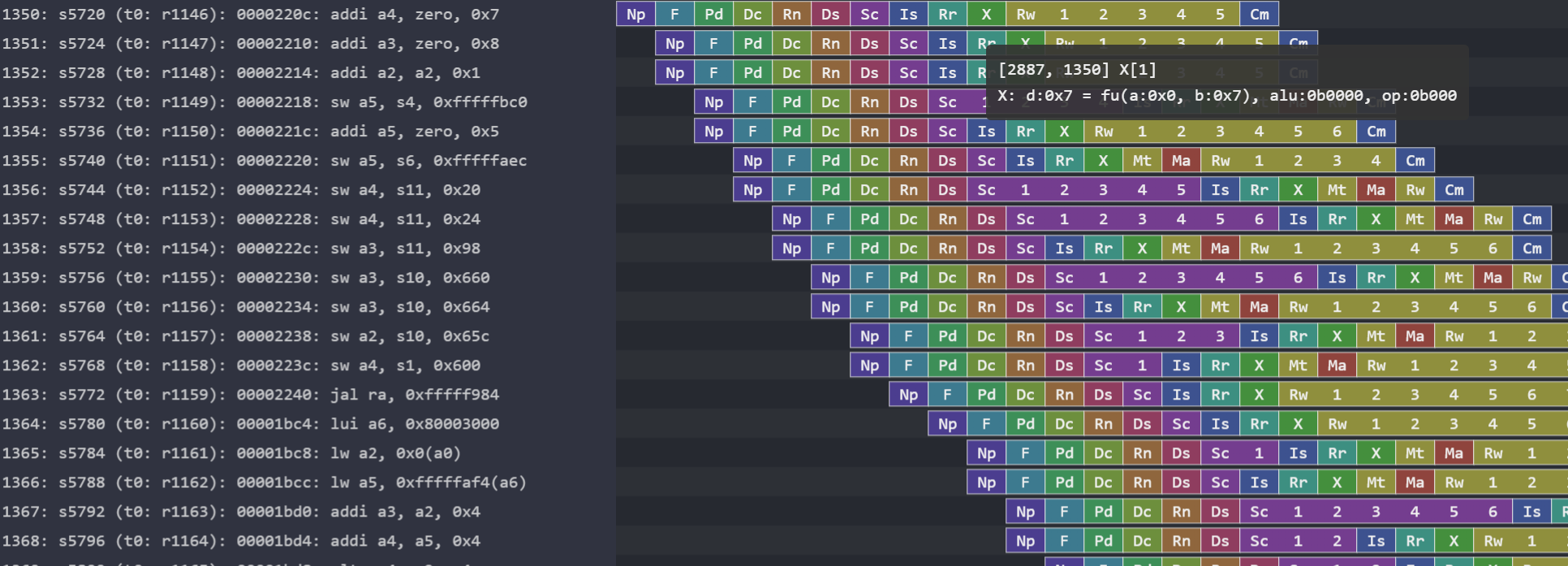
Hardware Abstractions: RTL
- Register-transfer level (RTL) (e.g. Verilog) is the lowest abstraction used in pre-silicon architecture evaluation
- Every bit of state and logic is explicitly modeled. RTL is the highest fidelity hardware model.
- Can extract very precise power, performance, and area metrics
Which Hardware Abstraction is Suitable?
- Architectural (functional) models
- Microarchitectural models ("rough") with approximate state and timing
- Microarchitectural models ("detailed") with more refined state and timing
- Register-transfer level (RTL) models with full fidelity state and timing
Can't compromise on accuracy or latency to enable meaningful and fast microarchitectural iteration.
"detailed" uArch models or RTL are the only options for our performance simulator selection
Can we Use Microarchitectural Simulators?
- uArch simulators seem to satisfy most of our requirements
- Low startup latency: seconds to 1 minute
- Metrics: IPC traces
- Cost: minimal
- Can we adapt uArch simulators to perform better in terms of accuracy and throughput?
Accuracy of Microarchitectural Simulators
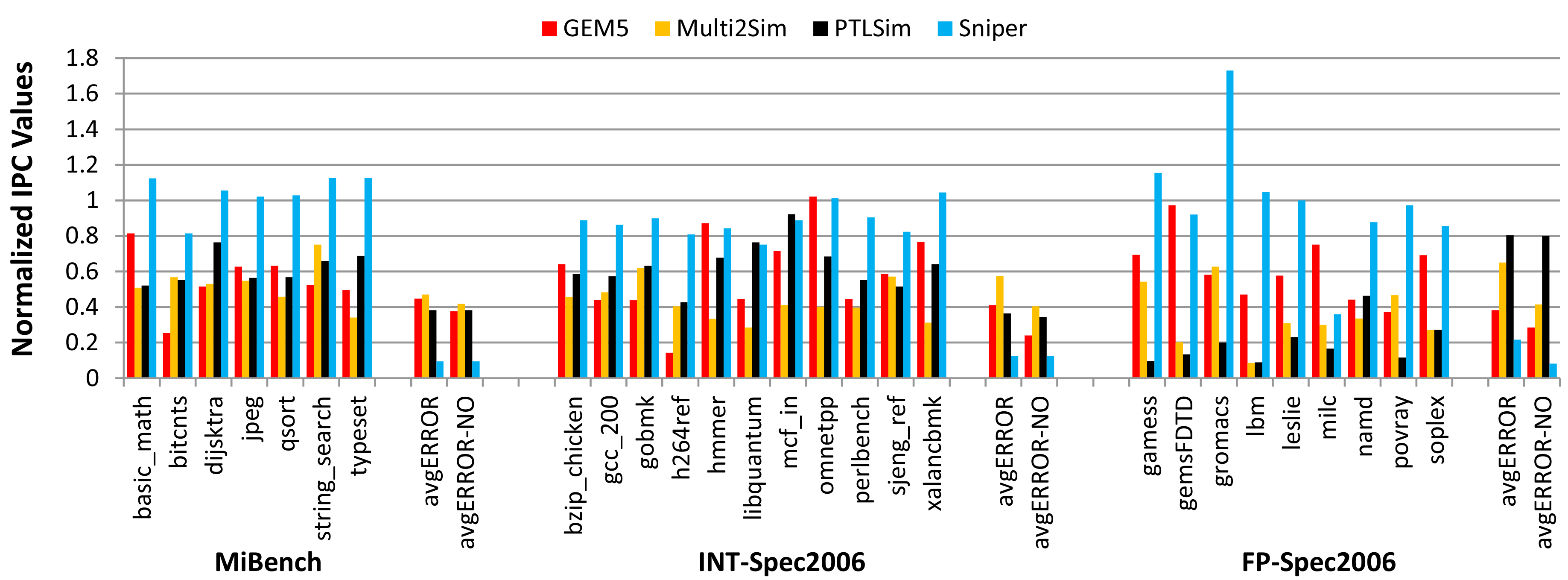
uArch simulators are not accurate enough for microarchitectural iteration.
Trends aren't enough. Note the sensitivity differences - gradients are critical!
[1]: Akram, A. and Sawalha, L., 2016, October. x86 computer architecture simulators: A comparative study. ICCD.
[2]: Akram, A. and Sawalha, L., 2019. A survey of computer architecture simulation techniques and tools. IEEE Access
Flexibility vs Accuracy Tradeoff of uArch Simulators
Sniper though shows greater accuracy, is not very flexible to allow one to model new micro-architectural features compared to gem5. On the other hand, gem5 and PTLsim are more flexible and can be used for studies of particular microarchitectural blocks, and full-system workloads, with gem5 being more configurable and showing higher accuracy. [1]
There is an unfavorable tradeoff of simulator flexibility (due to precise silicon calibration) and accuracy.
[1]: Akram, A. and Sawalha, L., 2019. A survey of computer architecture simulation techniques and tools. IEEE Access
The Trends Myth
It is casually stated as, “Although specific details of the simulation are wrong, the overall trends will be correct.”
Relative performance comparisons may be correct, even if there is absolute error caused by a poor assumption or bug.[1]
However, for this to be true, the new technique being evaluated through simulation must be insulated from or statistically uncorrelated with the source of simulation errors. Because simulators can have significant errors, which are completely unknown, only in rare cases can we be sure this argument holds.[1]
Even accurate relative trends are not enough for microarchitectural iteration - the gradients must also be precise!
[1]: Nowatzki, T., Menon, J., Ho, C.H. and Sankaralingam, K., 2015. Architectural simulators considered harmful. IEEE Micro.
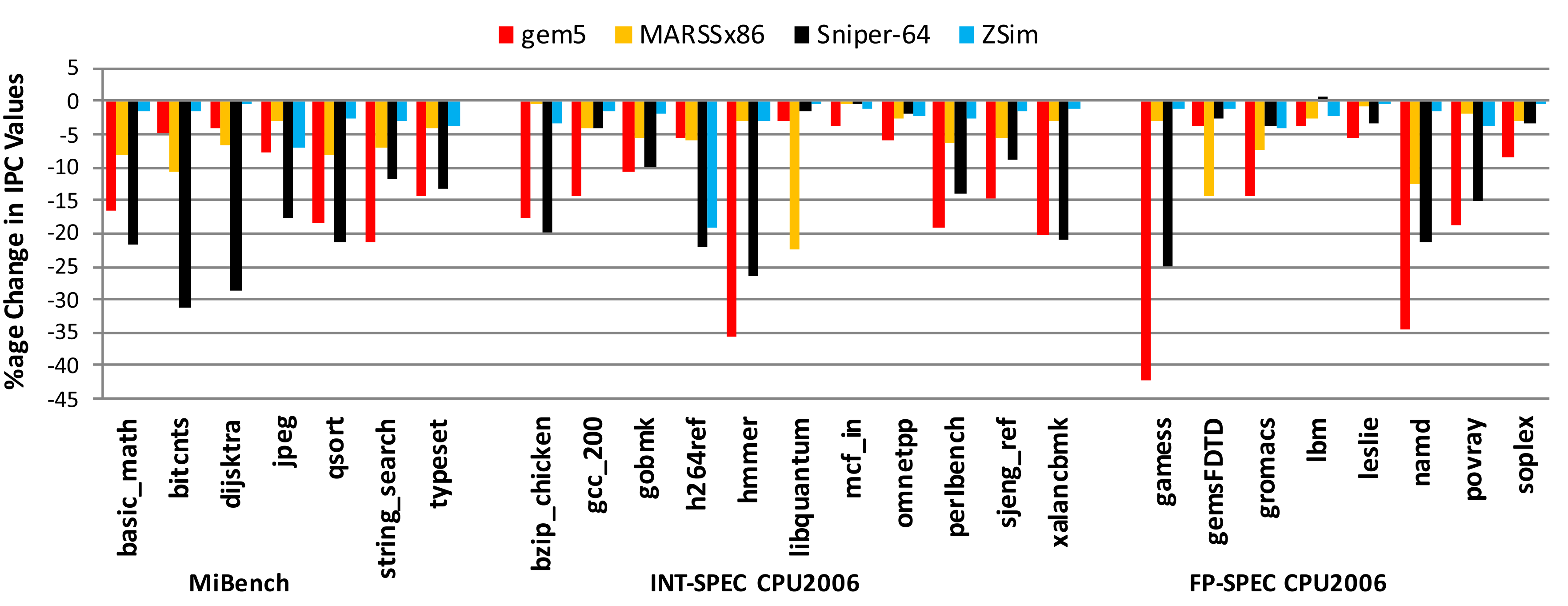
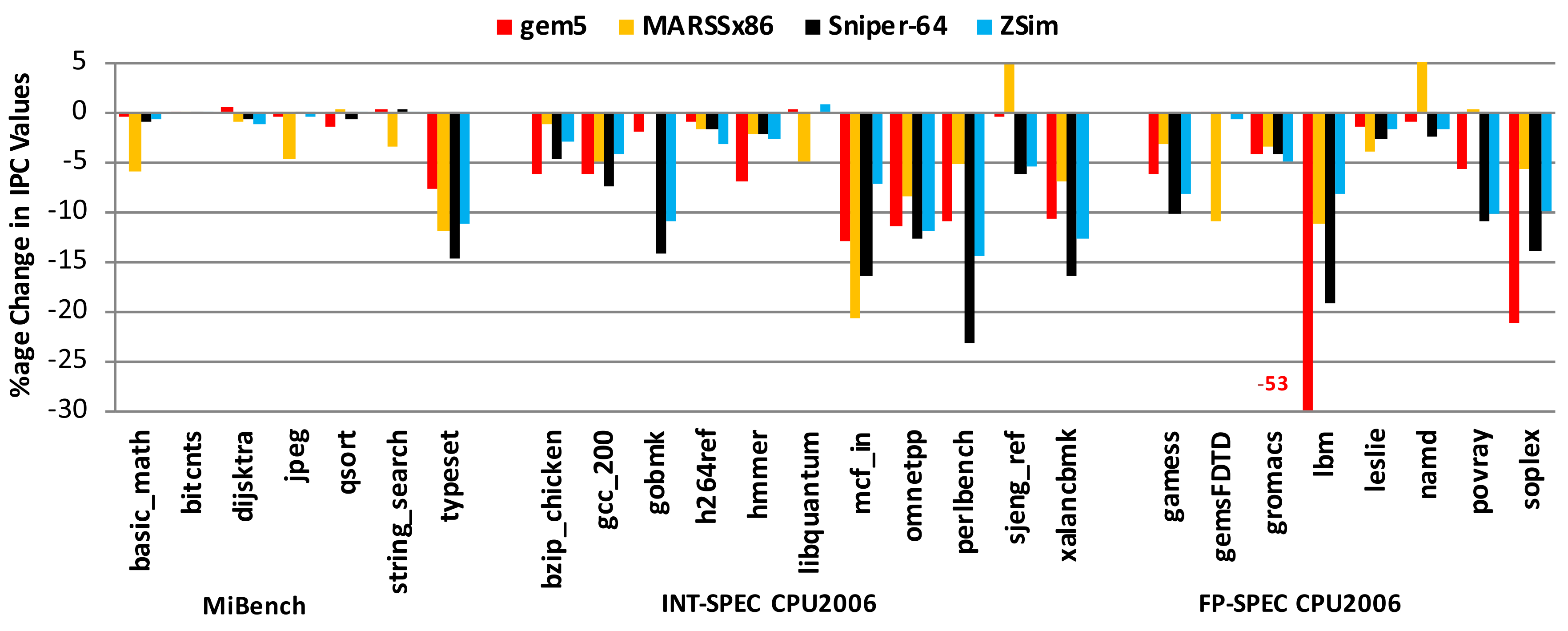
Accuracy of gem5 for RISC-V Cores
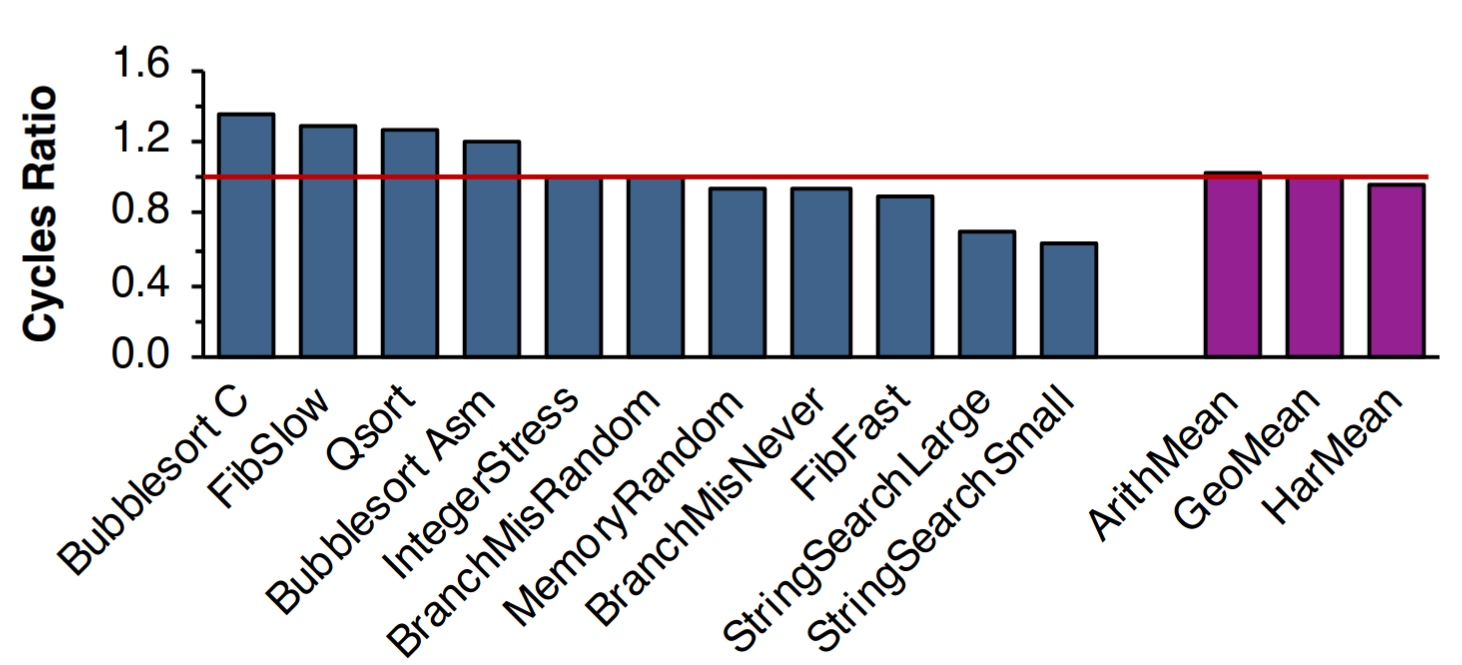
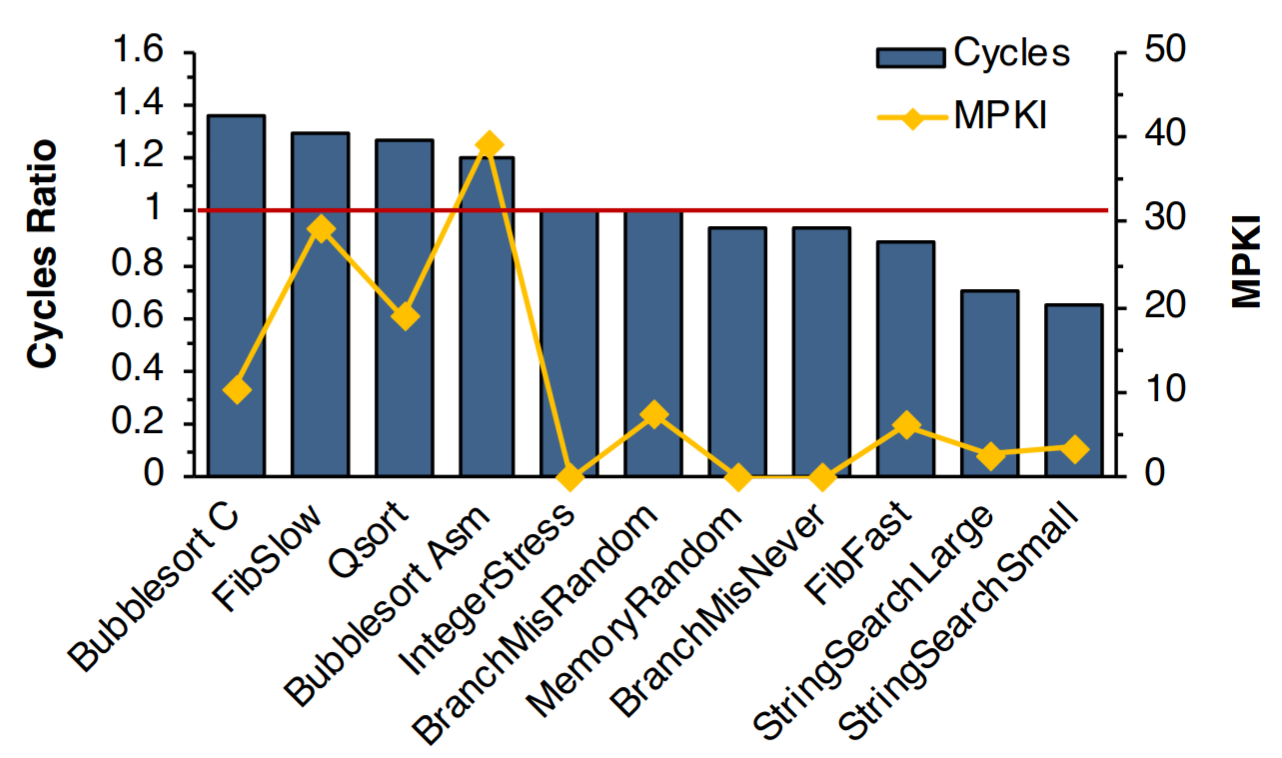

There is no evidence that uArch simulators can achieve sub 5% accuracy for microarchitectural iteration
[1]: Chatzopoulos, O., et. al., 2021. Towards Accurate Performance Modeling of RISC-V Designs. arXiv preprint
[2]: Ta, T., Cheng, L. and Batten, C., 2018. Simulating multi-core RISC-V systems in gem5. CARRV
But Can't We Calibrate uArch Simulators?
- [1] calibrates Sniper to Cortex A54 and A72 cores with average IPC errors of 7% and 15% (up to 50%) on SPEC CPU2017 respectively using ML to fine-tune model parameters against silicon measurements given microbenchmarks.
- [2] calibrates MARSSx86 to i7-920 with post-calibration IPC error of 7% on SPEC
- Absolute errors are still too high when architects must make decisions based on tiny IPC changes
- Calibration only applies to a specific design point!
- Gradients and errors are not understood nor bounded when microarchitecture parameters are altered to perform HW parameter DSE
uArch simulators are not suitable for pre-silicon microarchitectural iteration
[1]: Adileh, A., et al., 2019. Racing to hardware-validated simulation. ISPASS.
[2]: Asri, M., et al., 2016. Simulator calibration for accelerator-rich architecture studies. SAMOS
False Confidence from Validation
A common misconception is that if the parameters are changed and configured for some other design point, the accuracy will be similar.[1]
tool validation is often carried out by fitting parameters to the “specific” validation targets, not about ensuring the underlying modeling is accurate for individual phenomena or their interactions.[1]
Calibration / validation of a uArch simulator against silicon doesn't make it suitable for microarchitectural iteration
[1]: Nowatzki, T., Menon, J., Ho, C.H. and Sankaralingam, K., 2015. Architectural simulators considered harmful. IEEE Micro.
Our Decision Tree Thus Far
- Need high fidelity hardware abstractions → must use detailed uArch / RTL abstractions
- Need high accuracy simulators but uArch simulators are not accurate
- 1) absolutely, 2) with regards to relative trends and gradients, and 3) with regards to parameterizations
- Therefore, we must use RTL simulation as the lowest level performance simulator
But RTL simulation has low throughput!
Let's take a technique from uArch simulators that improves their throughput
Random Sampling
- Prior work: "SMARTS: Accelerating Microarchitecture Simulation via Rigorous Statistical Sampling"
- Before the workload is launched, the number of sampling units is determined
- If the sample variance is too high to achieve the target confidence bound, then more sampling units must be collected
- Sampling units are selected either using random, reservoir, or systematic sampling
- Central limit theorem is used to derive a confidence bound around the performance metrics reported by uArch simulation of the sampling units
Comparison Between Sampling Techniques
| Sampling Technique | Interval Length | # of Intervals Simulated | Interval Selection | Functional Warmup | Detailed Warmup | Time Granularity |
|---|---|---|---|---|---|---|
| SimPoint | 10-100M | 50-100 | BBFV + k-means | Optional | ≈0.1-1M | Interval length |
| SMARTS | 1-10k | 10k | Systematic sampling | Required | 1k | Entire workload |
| TidalSim | 10k | 10-100 | BBFV + k-means | Required | 1k | Interval Length |
Final Takeaways
- Microarchitectural iteration requires high accuracy
- → we must use RTL simulation as our performance simulator
- RTL simulation has low throughput
- → we must employ simulation sampling techniques to combine architectural and RTL simulation to improve throughput
- We can't execute long sampling units in RTL simulation
- → we must use uArch functional warmup models to minimize errors due to stale uArch state
- We want time-domain power, performance, and RTL collateral. We want the ability to extract tiny and unique benchmarks from large workloads.
- → we must combine the SimPoint and SMARTS sampling methodologies
4. How (pt 1): TidalSim v0.1
(A Prototype Implementation)
- Implementation details of the TidalSim v0.1 prototype
- Cache functional warmup model
- Results for IPC trace reconstruction
- Going from TidalSim v0.1 to v1
Overview of the TidalSim v0.1 Flow

Implementation Details For TidalSim v0.1
- Basic block identification
- BB identification from spike commit log or from static ELF analysis
- Basic block embedding of intervals
- Clustering and checkpointing
- k-means, PCA-based n-clusters
- spike-based checkpoints
- RTL simulation and performance metric extraction
- Custom force-based RTL state injection, out-of-band IPC measurement
- Extrapolation
- Estimate IPC of each interval based on its embedding and distances to RTL-simulated intervals
Functional Cache Warmup with Memory Timestamp Record
Memory Timestamp Record (MTR)[1] is a cache warmup model that can be constructed once and reused for many different cache parameterizations


[1]: Barr, Kenneth C., et al. "Accelerating multiprocessor simulation with a memory timestamp record." ISPASS 2005.
IPC Trace Prediction: huffbench
- Huffman compression from Embench (huffbench)
N=10000,C=18- Full RTL sim takes 15 minutes, TidalSim runs in 10 seconds
- Large IPC variance

IPC Trace Prediction: wikisort
- Merge sort benchmark from Embench (wikisort)
N=10000,C=18- Full RTL sim takes 15 minutes, TidalSim runs in 10 seconds
- Can capture general trends and time-domain IPC variation

Aggregate IPC Prediction for Embench Suite

Typical IPC error (without functional warmup and with fine time-domain precision of 10k instructions) is < 5%
Backup Slides
Basic Block Identification
Basic blocks are extracted from the dynamic commit trace emitted by spike
core 0: >>>> memchr
core 0: 0x00000000800012f6 (0x0ff5f593) andi a1, a1, 255
core 0: 0x00000000800012fa (0x0000962a) c.add a2, a0
core 0: 0x00000000800012fc (0x00c51463) bne a0, a2, pc + 8
core 0: 0x0000000080001304 (0x00054783) lbu a5, 0(a0)
core 0: 0x0000000080001308 (0xfeb78de3) beq a5, a1, pc - 6
- Control flow instructions mark the end of a basic block
- Previously identified basic blocks can be split if a new entry point is found
0: 0x8000_12f6 ⮕ 0x8000_12fc1: 0x8000_1304 ⮕ 0x8000_1308
Program Intervals
A commit trace is captured from ISA-level simulation
core 0: >>>> memchr
---
core 0: 0x00000000800012f6 (0x0ff5f593) andi a1, a1, 255
core 0: 0x00000000800012fa (0x0000962a) c.add a2, a0
core 0: 0x00000000800012fc (0x00c51463) bne a0, a2, pc + 8
---
core 0: 0x0000000080001304 (0x00054783) lbu a5, 0(a0)
core 0: 0x0000000080001308 (0xfeb78de3) beq a5, a1, pc - 6
core 0: 0x000000008000130c (0x00000505) c.addi a0, 1
---
The trace is grouped into intervals of $ N $ instructions of which we will choose $ C $ intervals as simulation units
Typical $C = 10-100$
Typical $N = 10000$
Interval Embedding and Clustering
Each interval is embedded with a vector indicating how often each basic block was ran
| Interval index | Interval length | Embedding |
|---|---|---|
| $ n $ | $ 100 $ | $ \begin{bmatrix}40 & 50 & 0 & 10\end{bmatrix} $ |
| $ n+1 $ | $ 100 $ | $ \begin{bmatrix}0 & 50 & 10 & 40\end{bmatrix}$ |
| $ n+2 $ | $ 100 $ | $ \begin{bmatrix}0 & 20 & 20 & 80\end{bmatrix}$ |
- Intervals are clustered using k-means clustering (typical $K = 10-30$)

- Centroids indicate which basic blocks are traversed most frequently in each cluster
- We observe that most clusters capture unique traversal patterns
Arch Snapshotting
For each cluster, take the sample that is closest to its centroid
Capture arch checkpoints at the start of each chosen sample
pc = 0x0000000080000332
priv = M
fcsr = 0x0000000000000000
mtvec = 0x8000000a00006000
...
x1 = 0x000000008000024a
x2 = 0x0000000080028fa0
...
Arch checkpoint = arch state + raw memory contents
RTL Simulation and Arch-State Injection
- Arch checkpoints are run in parallel in RTL simulation for $ N $ instructions
- RTL state injection caveats
- Not all arch state maps 1:1 with an RTL-level register
- e.g.
fflagsinfcsrare FP exception bits from FPU μArch state - e.g.
FPRsin Rocket are stored in recoded 65-bit format (not IEEE floats)
- Performance metrics extracted from RTL simulation
cycles,instret
1219,100
125,100
126,100
123,100
114,100
250,100
113,100
Challenges with RTL-Level Sampled Simulation
- As workload traces grow to billions of dynamic instructions, $N$ will have to go up too, to avoid too many clusters
- → we need to perform sampling unit subsampling using SMARTS-like methodology to tolerate the low throughput of RTL simulation
- Functional warmup can provide us with microarchitectural state at the start of each sampling unit, but injecting that state in RTL simulation is error-prone
- Correlating microarchitectural cache state via RTL hierarchical paths is tricky and requires manual effort
- If the hardware parameterization changes (cache hierarchy/sizing, choice of branch predictor)
- → the functional warmup models and state injection logic must also change
Extrapolation
- We gather performance metrics for one sampling unit in each cluster that is taken to be representative of that cluster ($\vec{p}$)
- To compute the estimated performance of a given interval
- Compute the distances $\vec{d}$ of that interval's embedding to each cluster centroid
- Compute a weighted mean using $\vec{d}$ and $\vec{p}$
- Compute the estimated performance of all intervals to extrapolate to a full performance trace
IPC Trace Prediction: aha-mont64
- Montgomery multiplication from Embench (aha-mont64)
N=1000,C=12- Full RTL sim takes 10 minutes, TidalSim runs in 10 seconds
- IPC is correlated (mean error <5%)

From Tidalsim v0.1 to v1
- Functional L1-only cache warmup
- Functional branch predictor warmup
- Characterization on other baremetal workloads
- dhrystone, coremark, riscv-tests benchmarks, MiBench
- Explore more sophisticated clustering and extrapolation techniques
- Demonstrate we can hit <1% IPC error
These milestones will set the stage for the qual proposal
5. Case Studies / Applications
- Hardware parameter DSE / microarchitecture optimization
- Coverpoint synthesis for verification
5.a: TidalSim for HW Parameter DSE
Demonstrate that use of TidalSim leads to better design decisions over RTL simulation and FireSim for a given compute budget.
Show how TidalSim enables quick fine-tuning of a core for a given workload.
5.a: Microarchitectural Optimizations and Workloads
-
Microarchitectural knobs to explore
- Prefetcher tuning[1]
- Workloads for tuning
- HyperCompressBench (baremetal), HyperProtoBench (Linux)
- Expected results
- RTL simulation → can evaluate only a few workloads, but with many design points
- FireSim → can evaluate many workloads, but only a few design points
- TidalSim → can evaluate many workloads and many design points
Many of Arm's efficiency gains come from small, microarchitectural level changes, mostly around how it implements data prefetch and branch prediction.
5.a: Leveraging HDLs for TidalSim Methodology
- HW DSE with TidalSim requires an RTL injection harness
- Automatic harness generation using high-level HDLs
- Chisel API to semantically mark arch and uArch state
- FIRRTL pass to generate a state-injecting test harness
class RegFile(n: Int, w: Int, zero: Boolean = false) {
val rf = Mem(n, UInt(w.W))
(0 until n).map { archStateAnnotation(rf(n), Riscv.I.GPR(n)) }
// ...
}
class L1MetadataArray[T <: L1Metadata] extends L1HellaCacheModule()(p) {
// ...
val tag_array = SyncReadMem(nSets, Vec(nWays, UInt(metabits.W)))
(0 until nSets).zip((0 until nWays)).map { case (set, way) =>
uArchStateAnnotation(tag_array.read(set)(way), Uarch.L1.tag(set, way, cacheType=I))
}
}
5.b: TidalSim for Verification

- Property synthesis techniques require waveforms for analysis
- Specification mining for invariant synthesis or RTL bug localization
- Coverpoint synthesis for tuning stimulus generators towards bugs
TidalSim provides a way to extract many small, unique, RTL waveforms from large workloads with low latency
5.b: Past Work on Specification Mining
- Take waveforms from RTL simulation and attempt to mine unfalsified specifications involving 2+ RTL signals[1]

- Specifications are constructed from LTL templates
- Until: $ \mathbf{G}\, (a \rightarrow \mathbf{X}\, (a\, \mathbf{U}\, b)) $
- Next: $ \mathbf{G}\, (a \rightarrow \mathbf{X}\, b) $
- Eventual: $ \mathbf{G}\, (a \rightarrow \mathbf{X F}\, b) $
- $a$ and $b$ are atomic propositions constructed from signals in the RTL design
[1]: Iyer, Vighnesh, et. al., 2019. RTL bug localization through LTL specification mining. MEMOCODE.
5.b: Specification Mining Used for RTL Bug Localization
Introduce a bug in the riscv-mini cache
- hit := v(idx_reg) && rmeta.tag === tag_reg
+ hit := v(idx_reg) && rmeta.tag =/= tag_reg
- This bug does not affect most ISA tests but a multiply benchmark failed by hanging
- Checking the VCD against the mined properties gives these violations
| Template | $\textbf{a}$ | $\textbf{b}$ | Violated at Time | |
|---|---|---|---|---|
| Until | Tile.arb_io_dcache_r_ready |
Tile.dcache.hit |
418 | |
| Until | Tile.dcache_io_nasti_r_valid |
Tile.dcache.hit |
418 | |
| Until | Tile.dcache.is_alloc |
Tile.dcache.hit |
418 | |
| Until | Tile.arb.io_dcache_ar_ready |
Tile.arb_io_nasti_r_ready |
640 |
The violated properties point to an anomaly with the hit signal and localize the bug
5.b: Coverpoint Synthesis as Complement of Spec Mining

- Coverpoint synthesis is an alternative take on spec mining where we synthesize μArch properties that we want to see more of
- Instead of monitoring properties just for falsification, we also monitor them for completion
- Properties that are falsified or completed, but not too often, are good candidates for coverpoints
- Evaluation
- Synthesize coverpoints on Rocket using waveforms from TidalSim and regular RTL sim with the same compute budget
- Demonstrate we can synthesize more, and more interesting coverpoints using TidalSim data
- Evaluate off-the-shelf RISC-V instgen on synthesized coverpoints vs structural coverage
6. How (pt 2): TidalSim v2
The proposal is structured as 3 novel extensions to TidalSim v1 that address its limitations in fundamental ways.
- Unvalidated functional warmup models
- → leverage verification libraries and fuzzing to automatically discover mismatches between the warmup model and RTL
- Inaccurate modeling of time-driven events (e.g. timer interrupts)
- → dynamically moving between arch and RTL simulation to estimate time
- Only works with processor cores and not heterogeneous IP
- → extend sampled simulation to accelerators
6.a: Validating Functional Warmup Models
Validation Flow
Functional warmup models need to be validated against the behavior of their modeled RTL

SimCommand: A Fast RTL Simulation API
- Testbench API embedded in Scala[1]
- Uses chiseltest as the simulator interface
- Functional: testbench description and interpretation are split
def enqueue(data: T): Command[Unit] = for {
_ <- poke(io.bits, data)
_ <- poke(io.valid, true.B)
_ <- waitUntil(io.ready, true.B)
_ <- step(1)
_ <- poke(io.valid, false.B)
} yield ()
- 20x faster than cocotb and chiseltest, parity with SystemVerilog + VCS
- Enables writing performant testbenches with fork/join constructs in Scala
[1]: Iyer, Vighnesh, et. al., SimCommand: A High Performance Multi-Threaded RTL Testbench API, OSCAR Workshop 2022
Parametric Random Stimulus Generators
- We designed a Scala eDSL for parametric random stimulus generation[1]
- Supports constrained and imperative randomization of Scala and Chisel datatypes
val intGen: Gen[Int] = Gen[Int].range(0, 100)
val seqGen: Gen[Seq[Int]] = for {
lit <- Gen.range(1, 100)
tailGen <- Gen.oneOf(Gen(Seq()) -> 0.1, seqGen -> 0.9),
seqn <- tailGen.map(t => lit +: t)
} yield seqn
object MemOp extends ChiselEnum
case class MemTx extends Bundle {
val addr = UInt(32.W)
val data = UInt(64.W)
val op = MemOp
}
val memTxGen: Gen[MemTx] = Gen[MemTx].uniform
[1]: Iyer, Vighnesh, et. al., New Embedded DSLs for HW Design and Verification, PLARCH Workshop 2023
RTL Coverage for Simulation Feedback

- Coverage implemented as a hardware IR compiler pass rather than baked into the RTL simulator
- Easy to add new coverage metrics via static analysis of the RTL netlist
- Leverage simulator independent coverage methodology for coverage instrumentation of long-lived uArch RTL
[1]: Laeufer, Kevin; Iyer, Vighnesh, et. al., Simulator Independent Coverage for RTL Hardware Languages, ASPLOS 2023
Parametric Fuzzing
- Leverage fast RTL simulation APIs, parametric stimulus generators, and coverage instrumentation for parametric fuzzing[1]

- Parametric fuzzing mutates the bytestream going into a parametric generator rather than the DUT directly[2]
- We augment typical parametric fuzzing with mark-driven mutation
[1]: Iyer, Vighnesh, et. al., New Embedded DSLs for HW Design and Verification, PLARCH Workshop 2023
[2]: Padhye, R., Lemieux, C., Sen, K., Papadakis, M. and Le Traon, Y., 2019. Semantic fuzzing with zest. ACM SIGSOFT.
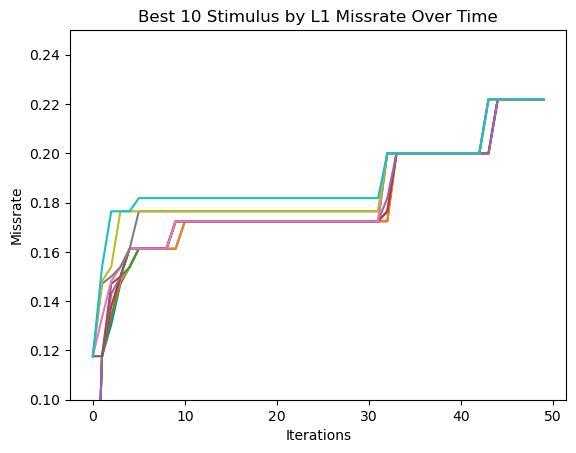
Parametric Fuzzing - Demo Using Spike

- Use spike's L1 dcache model's miss rate as feedback to produce RISC-V programs that maximize it
- Using parametric fuzzing, we can automatically construct RISC-V programs to maximize any uArch metric given a small set of RISC-V sequence primitives
6.b: Putting the 'Tidal' in TidalSim
Issues with Time Modeling in Sampled Simulation
- Prior work runs uArch simulators in "syscall emulation" mode when evaluating workloads (e.g. SPEC), not modeling any OS-application interactions
- Real workloads contain many interactions between processes and the OS which are sensitive to the modeling of time

Consider timer interrupts: naive functional simulators will just advance one timestep per commited instruction, not matching RTL!
TidalSim to Model Time Accurately
- We propose bouncing between functional and RTL simulation, where performance metrics from RTL sim impacts time advancement in functional sim
- To avoid simulating every interval in RTL sim, we leverage interval embeddings to estimate IPC on the fly
6.c: Sampled Simulation with Accelerators
What Makes Accelerators Suitable for Sampled Simulation?
- Accelerator architectural state is large and explicit
- → snapshotting is easy
- → functional warmup is unnecessary
- Accelerator usage is often repeated in workloads
- → clustering accelerator usage embeddings is reasonable
- → potential for massive simulation throughput improvement
- Accelerator behavior is consistent
- → accelerator performance is consistent from one dataset to another
- → embeddings don't need to be aware of the accelerator microarchitecture / latent state
Extending Interval Embeddings to Accelerators

- Incorporate accelerator state and the semantics of the accelerator ISA to the embedding
- Can capture and embed accelerator interactions with system memory and with internal compute units
- In the case of Gemmini, we must also consider instruction dependencies and out-of-order execution + memory contention from multiple accelerators
Backup: 6.d: Generalizing the Spectrum of Sampled Simulation
Sampled Simulation Techniques

Simulation techniques encompass SMARTS, SimPoint, hybrid variants, eager parallel RTL simulation, and many more
A Formalization and Simulation Model
- Only considering techniques that can operate in a streaming fashion, develop a parameterized version of TidalSim
- Streaming necessitates new incremental unsupervised learning algorithms
- Formalize the interfaces between arch sim, uArch models, and RTL sim
- Formalize and parameterize simulation methodology to encompass all prior techniques
- Consider input parameters such as interval length ($N$), number of host cores ($n_{cores}$), RTL simulation throughput ($T_{rtl}$), sampling technique ($i \rightarrow \{0, 1\}$)
- Produce estimated output metrics such as cost, runtime, aggregate throughput, latency, time-granularity of output, error bounds
PC/Binary-Agnostic Embeddings
- Basic block embedding assumes
- There is a static PC → basic block mapping
- Intervals with similar basic block traversals have similar uArch behavior
- Our embeddings should be PC/binary-agnostic to support portability and multi-process workloads in an OS
- Most prior work only runs single-process workloads using syscall proxies
- Real workloads are heavily affected by interactions between the OS and userspace processes
- We will explore embeddings with features such as
- Instruction mix, function call frequency, instruction dependencies
- Microarchitectural behaviors: I/D cache misses, BP model mispredicts, TLB behavior
7. Thesis Outline
Outline
- Motivation and background
- Implementation and evaluation of TidalSim v0.1 - Completed
- Mixed functional/RTL simulation, IPC/MPKI/cache behavior estimation
- Clean estimation on all baremetal workloads (MiBench, Embench)
- Implementation and evaluation of TidalSim v1 - March 2024
- Functional warmup of all long-lived units
- Demonstrate <1% IPC error
- Validating functional warmup models - May 2024
- SimCommand, parametric stimulus generation APIs, parametric fuzzing
- Heuristics for comparing functional models and RTL uArch structures
- Modeling time accurately - June 2024
- Dynamically switching between RTL and functional simulation for modeling time accurately
- Time estimation fidelity, comparison to FireSim in modeling timer interrupts
- Sampled simulation for accelerators - August 2024
- New embeddings for code that uses accelerators
- Using TidalSim for hardware DSE - September 2024
- Language-level support for arch/uArch state marking and testharness synthesis
- Prefetcher optimization case study to show superior DSE latency and accuracy vs other approaches
- Using TidalSim for coverpoint synthesis - November 2024
Problem Overview
Fast RTL-level μArch simulation and performance metric / interesting trace extraction
enables
Rapid RTL iteration with performance, power modeling, and verification evaluation on real workloads
How can we achieve high throughput, high fidelity, low latency μArch simulation with RTL-level interesting trace extraction?
Motivation
- We want fast design iteration and evaluation of PPA + verification given real workloads
- The enablers are: fast and accurate μArch simulation and a way to identify unique execution fragments
- Performance estimation: Performance metric extraction from fast RTL simulation
- Power macromodeling: Extraction of interesting program traces for clustering/training
- Verification: Extraction of traces for coverpoint/specification synthesis + state seeding for fuzzing
Pre-Silicon Microarchitecture Simulation
- Performance estimation: Impact of μArch optimizations / HW parameters on real workloads
- Power macromodeling: Identification of important netlist nodes in power model + traces for training
- Verification: Bootstrapping fuzzing loops + coverpoint synthesis
Performance Optimizations
- Currently two runs of the binary through spike are needed
- One to get a commit log for basic block extraction, embedding, and clustering
- One more to dump arch checkpoints for chosen samples
- We can take regular checkpoints during the first execution to make arch checkpoint collection fast
Validation of State Injection
- There is no arch state comparison at the end of a checkpoint run in RTL simulation
- We will standardize a arch state schema and dump a reference state from spike to check against
Handling Large Interval Lengths
- Real programs will use large intervals (1-10M instructions)
- Selected intervals can't be run in their entirety in RTL simulation
- Sub-sampling intervals with random sampling is required
Conclusion
- We want rapid iteration wrt PPA evaluation and verification objectives
- We need fast RTL-level simulation with trace extraction
- We propose TidalSim, a multi-level simulation methodology to enable rapid HW iteration