TidalSim: Multi-Level Microarchitecture Simulation
Vighnesh Iyer, Raghav Gupta, Dhruv Vaish, Charles Hong, Young-Jin Park, Sophia Shao, Bora Nikolic
SLICE Winter Retreat 2024
Wednesday, January 10th, 2024
Motivation
Trends in SoC Evolution
End of Moore's Law
→ $/transistor not falling
→ Transistors are no longer free
→ Need aggressive PPA optimization
End of Dennard Scaling
→ Power density increasing
→ GPP performance stagnating
→ Need domain-specialization to not stagnate
Motivates two trends in SoC design
- Heterogeneous cores
- Cores targeting different power/performance curves
- Domain-specific cores
- Core-coupled accelerators (ISA extensions)
- Domain-specific accelerators
The New-Era of Domain-Specialized Heterogeneous SoCs
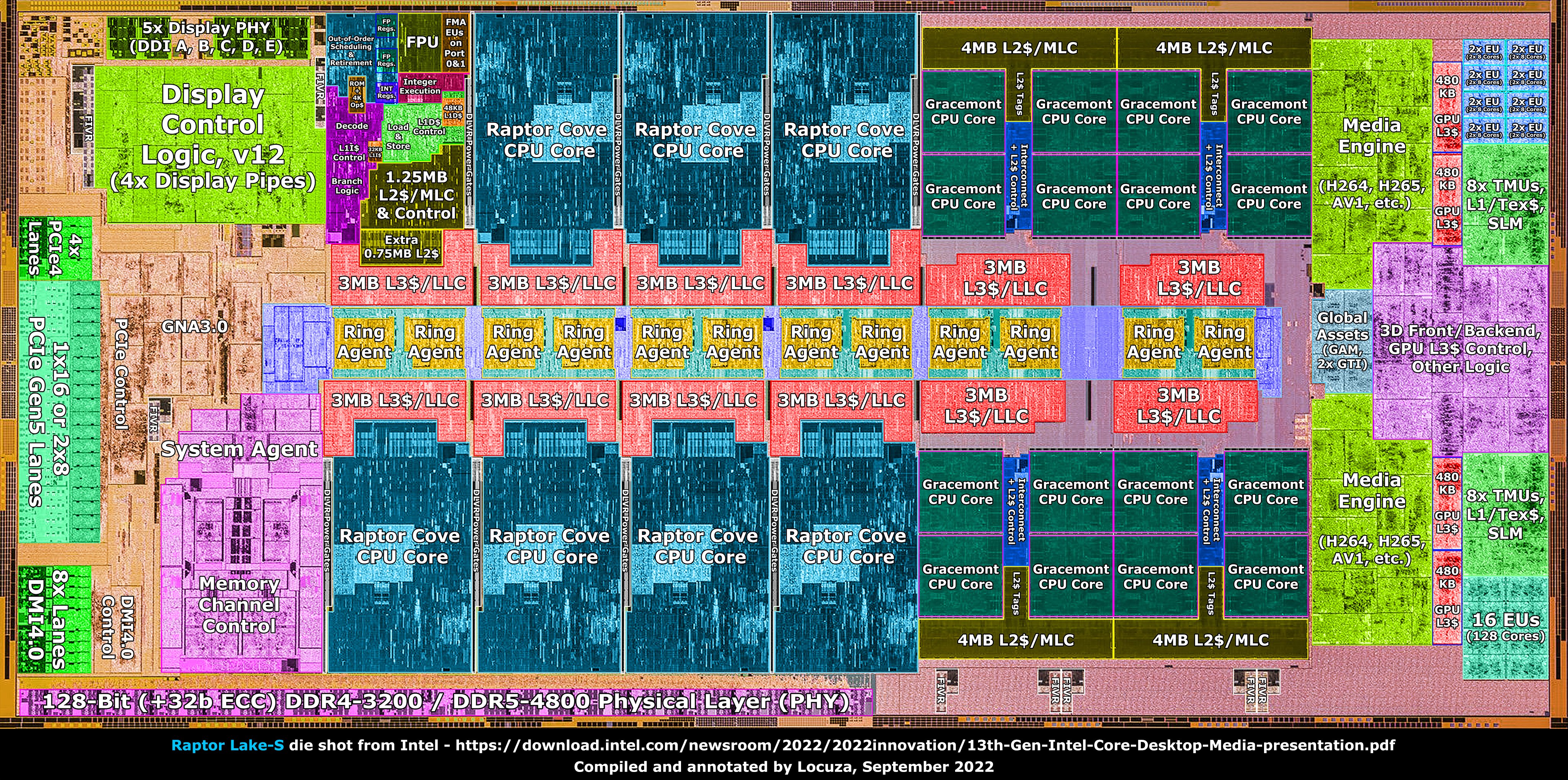
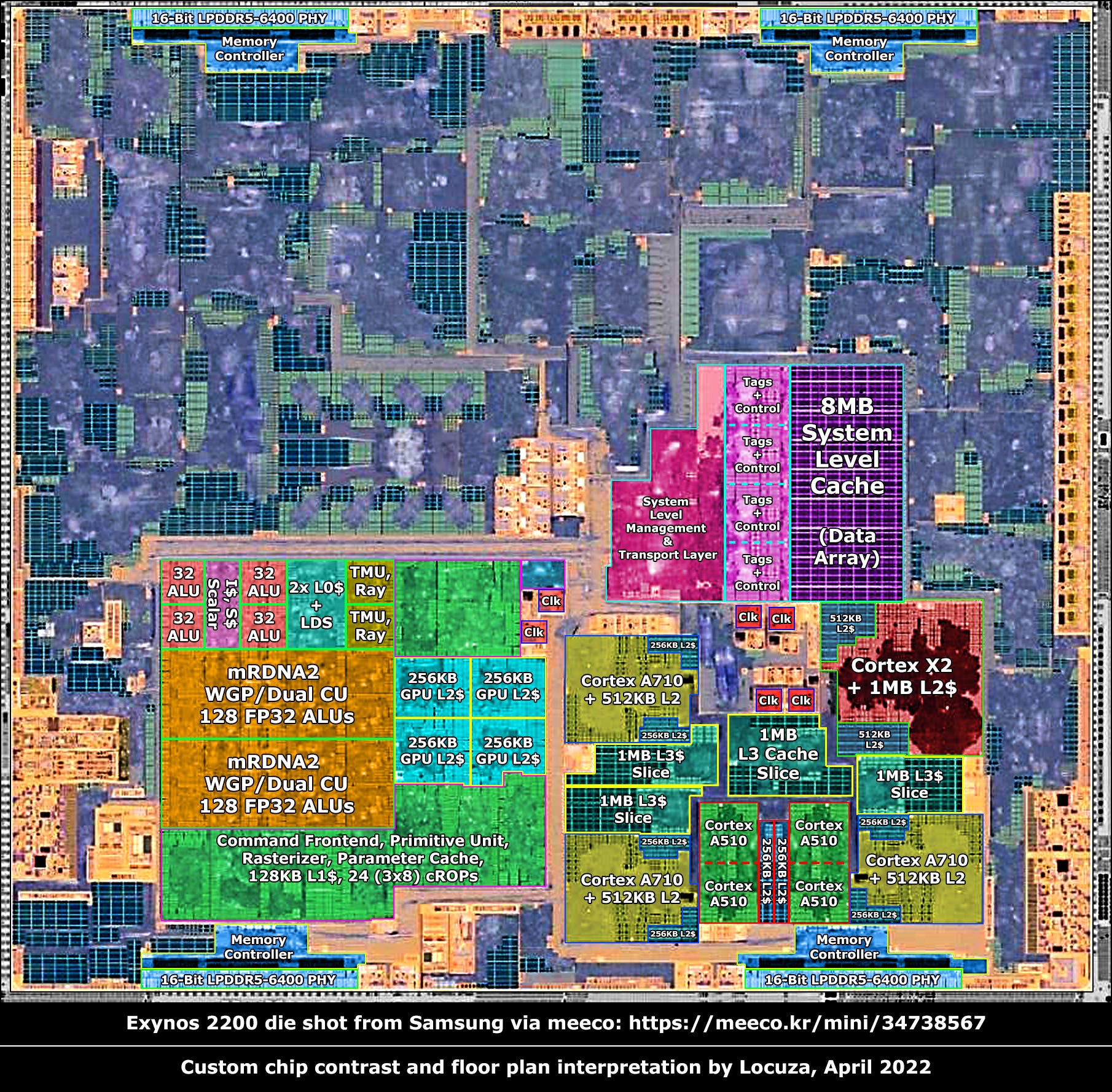
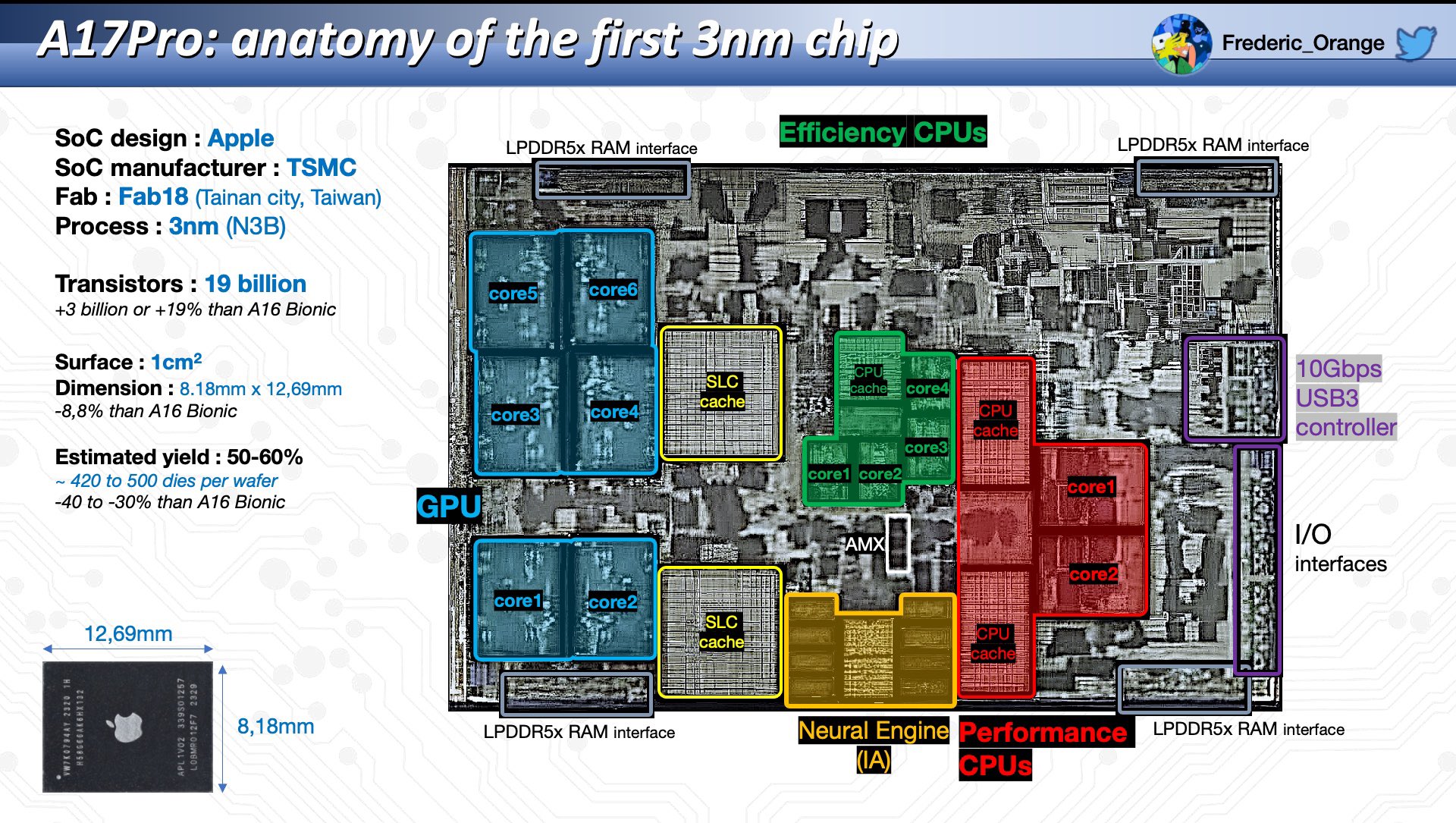
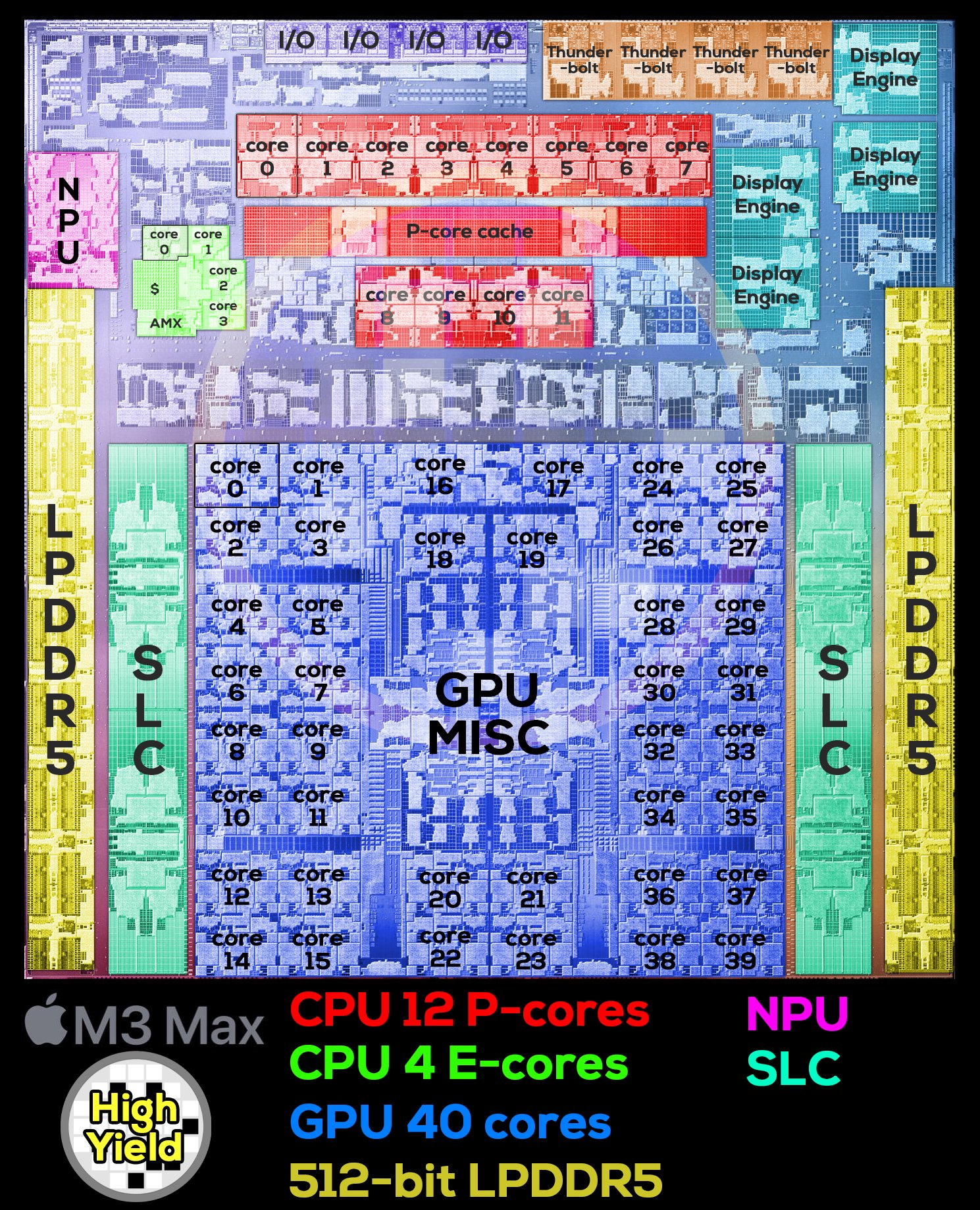
Microarchitecture Design Challenges
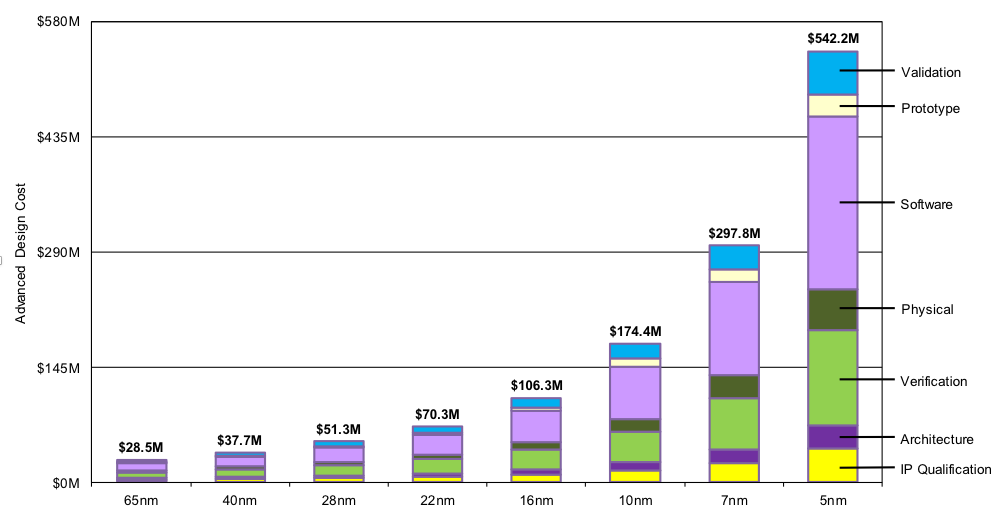
- We want optimal designs for heterogeneous, domain-specialized, workload-tuned SoCs
- Limited time to iterate on microarchitecture and optimize PPA on real workloads
- Time per evaluation (microarchitectural iteration loop) limits number of evaluations
More evaluations = more opportunities for optimization
The Microarchitectural Iteration Loop

We want an "Evaluator" that has low latency, high throughput, high accuracy, low cost, and rich output collateral
Existing tools cannot deliver on all axes
Limitations of Existing Evaluators
- ISA simulation: no accuracy
- Trace/Cycle uArch simulation: low accuracy (10-50% IPC error is typical), medium throughput (gem5 = 100 KIPS)
- RTL simulation: low throughput (10 KIPS)
- FPGA prototype / emulator: high latency (2-6 hours)
- HW emulators: high cost ($10M+)
We will propose a simulator that can deliver on all axes.
Our Vision for TidalSim
What if we had a simulator that:
- Is fast enough to run real workloads on heterogeneous SoCs
- Is accurate enough to use confidently for microarchitectural DSE
- Has low latency to not bottleneck the hardware iteration loop
- Can produce RTL-level collateral for applications from power modeling to application-level profiling to verification
- Can automatically isolate and extract benchmarks from long workloads by identifying unique aspects with respect to power, performance, and functionality
TidalSim

Background: Sampled Simulation
Phase Behavior of Programs
- Program execution traces aren’t random
- They execute the same code again-and-again
- Application execution traces can be split into phases that exhibit similar μArch behavior
- Prior work: SimPoint
- Identify basic blocks executed in a given interval (e.g. 1M instruction intervals)
- Embed each interval using their ‘basic block vector’
- Cluster intervals using k-means
- Similar intervals → similar μArch behaviors
- Only execute unique intervals in low-level RTL simulation!

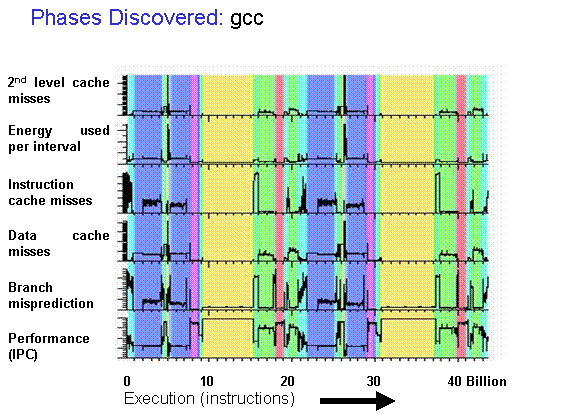
Sampled Simulation
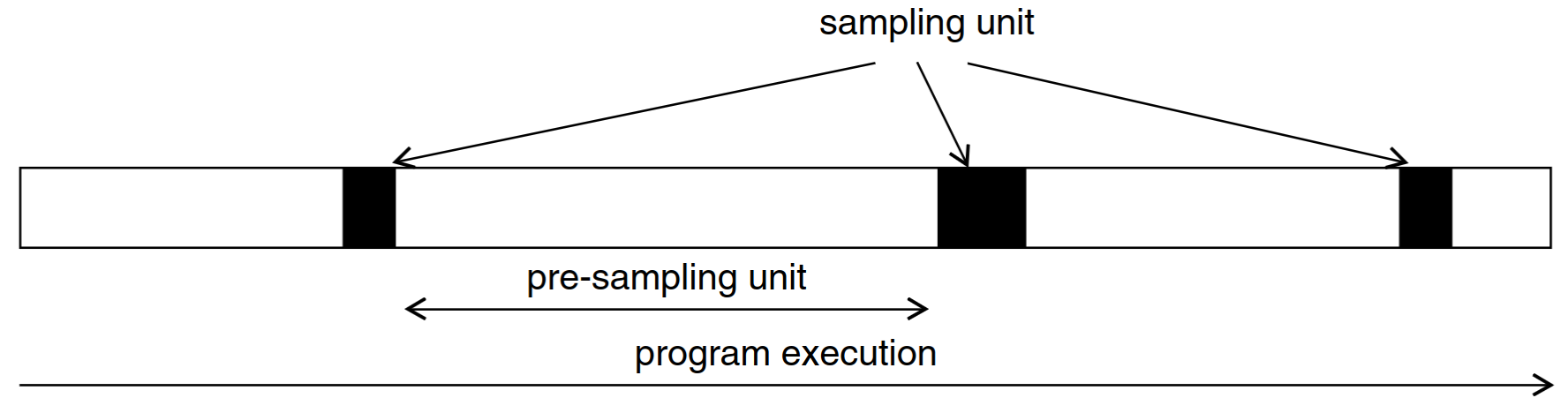
- Sampled simulation only executes specific intervals (sampling units) of the full workload in detailed performance simulation
- The sampling units are chosen based on embeddings or randomly

- Functional warmup initializes the long-lived uArch state (caches, TLB, branch predictor, prefetcher) in performance simulation
- Detailed warmup initializes the short-lived uArch state (pipeline, ROB, LSU)
- The sampled intervals are used to reconstruct the full IPC trace of the workload
Sampling Techniques
| Sampling Technique | Interval Length | # of Intervals Simulated | Interval Selection | Functional Warmup | Detailed Warmup | Time Granularity |
|---|---|---|---|---|---|---|
| SimPoint | 10-100M | 50-100 | BBFV + k-means | Optional | ≈0.1-1M | Interval length |
| SMARTs | 10-100k | 10k | Reservoir sampling | Required | 1k | Entire workload |
| TidalSim | 10k | 10-100 | BBFV + k-means | Required | 1k | Interval Length |
What's Different vs Regular Sampled Perf Sim?
TidalSim leverages RTL simulation for performance estimation!
- No need to perform correlation between perf model and RTL
- Error is introduced by sampling, but it can be understood/bounded with statistical methods
- Additional error comes from modeling RTL constructs (which is often done poorly and can't be bounded)
- Possible to derive accurate PPA numbers
- Real frequency and area numbers from synthesis
- Can extrapolate up to full power traces
- Leverage special collateral (waveforms) from RTL simulation
- Power macromodel construction and training
- Coverpoint synthesis, bootstrapping RTL fuzzing
Multi-level simulation with RTL-level injection hasn't been done before. So we should try!
TidalSim v0.1 Prototype
Components of TidalSim Flow
- Basic block identification
- BB identification from spike commit log or from static ELF analysis
- Basic block embedding of program intervals
- Clustering and checkpointing
- k-means, PCA-based n-clusters, spike-based checkpoints
- RTL simulation and performance metric extraction
- Custom force-based RTL state injection, out-of-band IPC measurement
- Extrapolation

Basic Block Identification
Basic blocks are extracted from the dynamic commit log emitted by spike
core 0: >>>> memchr
core 0: 0x00000000800012f6 (0x0ff5f593) andi a1, a1, 255
core 0: 0x00000000800012fa (0x0000962a) c.add a2, a0
core 0: 0x00000000800012fc (0x00c51463) bne a0, a2, pc + 8
core 0: 0x0000000080001304 (0x00054783) lbu a5, 0(a0)
core 0: 0x0000000080001308 (0xfeb78de3) beq a5, a1, pc - 6
- Control flow instructions mark the end of a basic block
- Previously identified basic blocks can be split if a new entry point is found
0: 0x8000_12f6 ⮕ 0x8000_12fc1: 0x8000_1304 ⮕ 0x8000_1308
Interval Embedding and Clustering
Embed each interval with the frequency it traversed every identified basic block
| Interval index | Interval length | Embedding |
|---|---|---|
| n | 100 | [40, 50, 0, 10] |
| n+1 | 100 | [0, 50, 10, 40] |
| n+2 | 100 | [0, 20, 20, 80] |
Intervals are clustered using k-means clustering on their embeddings
Arch Snapshotting
For each cluster, take the sample that is closest to its centroid
Capture arch checkpoints at the start each chosen sample
pc = 0x0000000080000332
priv = M
fcsr = 0x0000000000000000
mtvec = 0x8000000a00006000
...
x1 = 0x000000008000024a
x2 = 0x0000000080028fa0
...
An arch checkpoints = arch state + raw memory contents
RTL Simulation and Arch-State Injection
- Arch checkpoints are run in parallel in RTL simulation for N instructions
- RTL state injection caveats
- Not all arch state maps 1:1 with an RTL-level register
- e.g.
fflagsinfcsrare FP exception bits from FPU μArch state - e.g.
FPRsin Rocket are stored in recoded 65-bit format (not IEEE floats)
- Performance metrics extracted from RTL simulation
cycles,instret
1219,100
125,100
126,100
123,100
114,100
250,100
113,100
Extrapolation
Performance metrics for one sample in a cluster are representative of all samples in that cluster
Extrapolate on the entire execution trace to get a full IPC trace
DEMO!
Running TidalSim on the Embench Wikisort benchmark (~2M dynamic instructions) and reconstructing an IPC trace.
Results
Clustering on Embench Benchmarks
- Cluster centroids indicate which basic blocks are traversed most frequently in each cluster

- We observe that most clusters capture unique traversal patterns
IPC Trace Prediction
- Montgomery multiplication from Embench (aha-mont64)
N=1000,C=12- Full RTL sim takes 10 minutes, TidalSim runs in 10 seconds
- IPC is correlated (mean error <5%)

IPC Trace Prediction
- Huffman compression from Embench (huffbench)
N=10000,C=18- Full RTL sim takes 15 minutes, TidalSim runs in 10 seconds
- Larger IPC variance

Aggregate IPC Prediction for Embench Suite

Typical IPC error (without functional warmup) is < 5%
Work in Progress
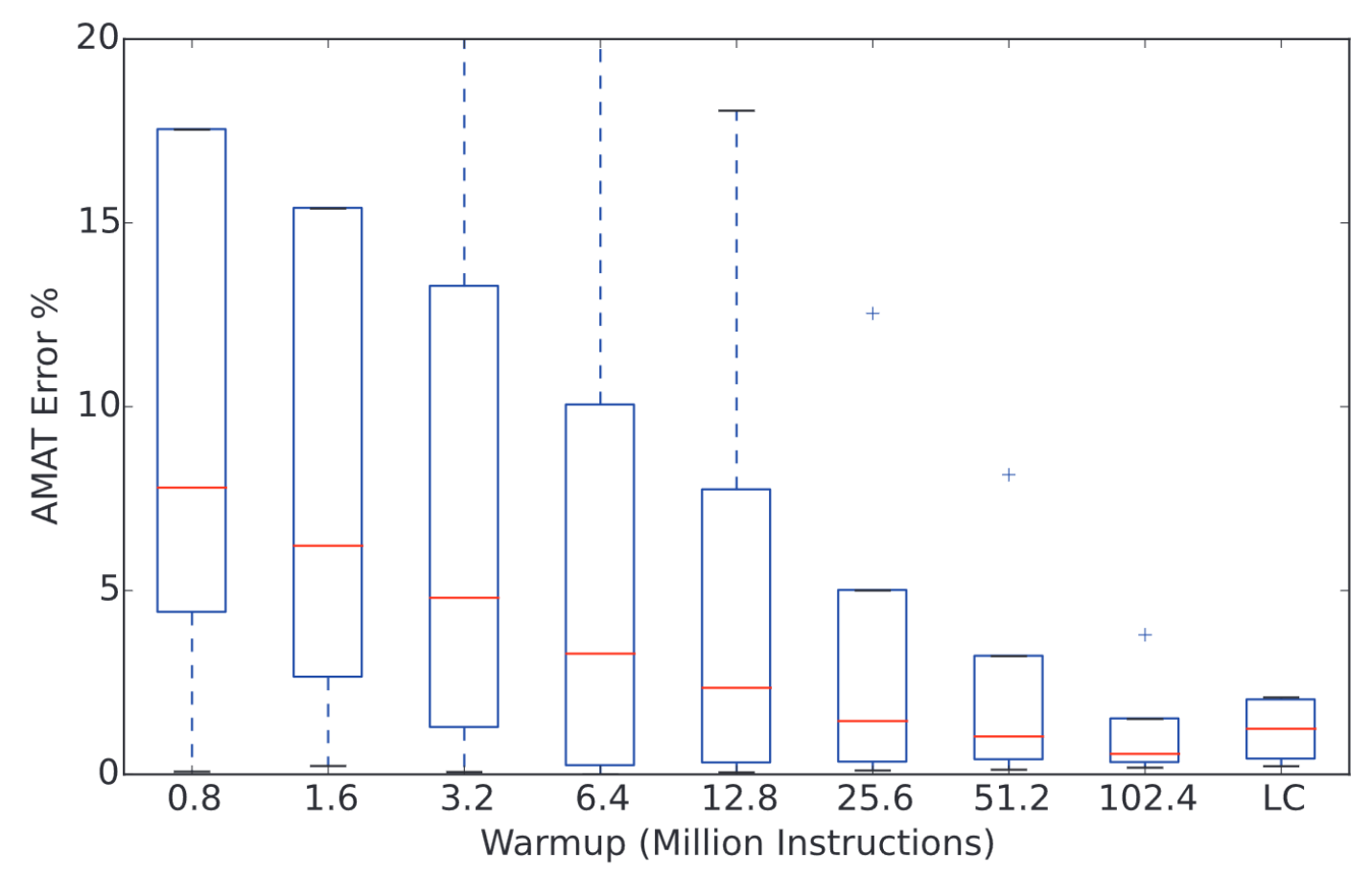
Functional Cache Warmup
- Each checkpoint is run in RTL simulation with a cold cache → inaccurate IPC due to incomplete cache warming during detailed warmup
- WIP: "Memory Timestamp Record"[2] based cache model and RTL cache state injection
[1]: Hassani, Sina, et al. "LiveSim: Going live with microarchitecture simulation." HPCA 2016.
[2]: Barr, Kenneth C., et al. "Accelerating multiprocessor simulation with a memory timestamp record." ISPASS 2005.
Dealing with Long-Lived μArch State

- Caches aren't the only long-lived CPU structures
- A general warmup methodology ingests a subset of a functional simulation log
- Each unit needs a custom model, injection logic, and perf metric extraction
- Generation of state injection test harness from Chipyard SoC generator
Application: Coverpoint Synthesis
- Specification mining takes waveforms of an RTL design and synthesizes properties involving 2+ signals that are unfalsified on all traces
- Coverpoint synthesis is an alternative take on spec mining where we synthesize μArch properties that we want to see more of
- This technique is far more effective if we have many unique, realistic traces
- Leverage interval clustering and sampled RTL simulation
Conclusion
- We want to enable rapid RTL iteration with performance evaluation and generation of RTL-level collateral
- We need fast RTL-level simulation
- We propose TidalSim, a multi-level simulation methodology to enable rapid HW iteration
TidalSim (github.com/euphoric-hardware/tidalsim) Forks of spike, chipyard, testchipip + top-level runner