TidalSim: Fast and Accurate Microarchitectural Simulation via Sampled RTL Simulation
Vighnesh Iyer, Raghav Gupta, Dhruv Vaish, Charles Hong, Sophia Shao, Bora Nikolic
Overview for Intel
Tuesday, March 5th, 2024
Talk Outline
- Motivation
- What is TidalSim?
- Background on Sampled Simulation
- Our Prototype Implementation
- Functional Warmup for Sampled RTL Simulation
- Next steps
- Taking multiple samples per cluster
- Binary-agnostic interval embeddings
- Streaming sampled simulation
- FIRRTL pass for injection testharness generation
Motivation
Microarchitecture Design Challenges
- We want optimal designs for heterogeneous, domain-specialized, workload-tuned SoCs
- Limited time to iterate on microarchitecture and optimize PPA on real workloads
- Time per evaluation (microarchitectural iteration loop) limits number of evaluations
More evaluations = more opportunities for optimization
The Microarchitectural Iteration Loop

We want an "Evaluator" that has low latency, high throughput, high accuracy, low cost, and rich output collateral
Existing tools cannot deliver on all axes
Existing Hardware Simulation Techniques
| Examples | Throughput | Latency | Accuracy | Cost | |
|---|---|---|---|---|---|
| JIT-based Simulators / VMs | qemu, KVM, VMWare Fusion | 1-3 GIPS | <1 second | None | Minimal |
| Architectural Simulators | spike, dromajo | 10-100+ MIPS | <1 second | None | Minimal |
| General-purpose μArch Simulators | gem5, Sniper, ZSim, SST | 100 KIPS (gem5) - 100 MIPS (Sniper) | <1 minute | 10-50% IPC error | Minimal |
| Bespoke μArch Simulators | Industry performance models | ≈ 0.1-1 MIPS | <1 minute | Close | $1M+ |
| RTL Simulators | Verilator, VCS, Xcelium | 1-10 KIPS | 2-10 minutes | Cycle-exact | Minimal |
| FPGA-Based Emulators | Firesim | ≈ 10 MIPS | 2-6 hours | Cycle-exact | $10k+ |
| ASIC-Based Emulators | Palladium, Veloce | ≈ 0.5-10 MIPS | <1 hour | Cycle-exact | $10M+ |
| Multi-level Sampled Simulation | TidalSim | 10+ MIPS | <1 minute | <1% IPC error | Minimal |
Our Proposal
What if we had a simulator that:
- Is fast enough to run real workloads on heterogeneous SoCs
- Is accurate enough to use confidently for microarchitectural DSE
- Has low latency to not bottleneck the hardware iteration loop
- Can produce RTL-level collateral for applications from power modeling to application-level profiling to verification
- Can automatically isolate and extract benchmarks from long workloads by identifying unique aspects with respect to power, performance, and functionality
TidalSim Overview

TidalSim Components

TidalSim is not a new simulator. It is a simulation methodology that combines the strengths of architectural simulators, uArch models, and RTL simulators.
TidalSim Execution

Background on Sampled Simulation
Sampled Simulation
Instead of running the entire program in uArch simulation, run the entire program in functional simulation and only run samples in uArch simulation
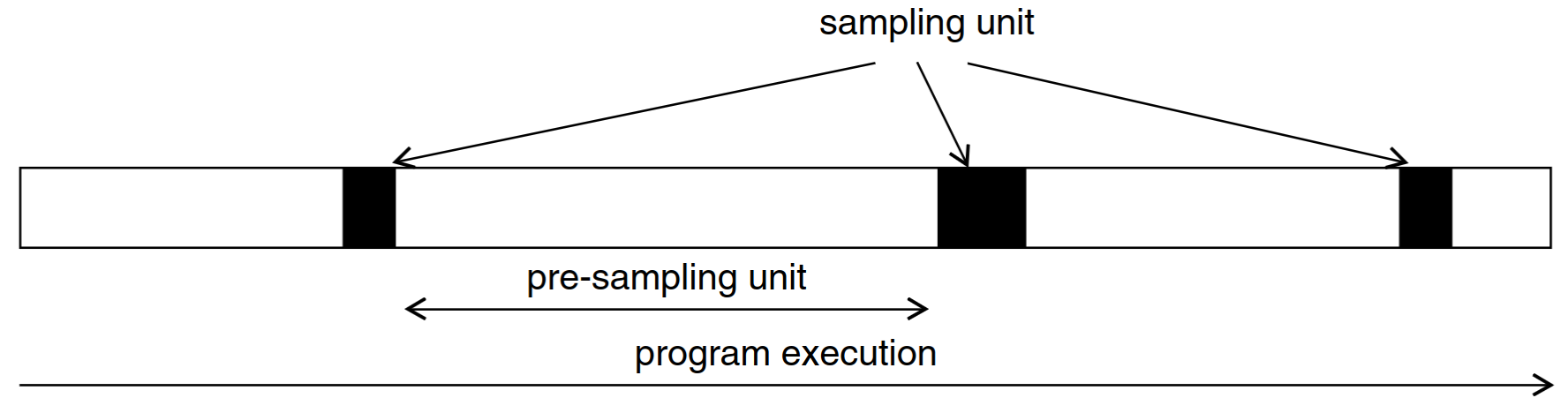
The full workload is represented by a selection of sampling units.
- How should sampling units be selected?
- How can we accurately estimate the performance of a sampling unit?
- How can we estimate errors when extrapolating from sampling units?
Existing Sampling Techniques
SimPoint

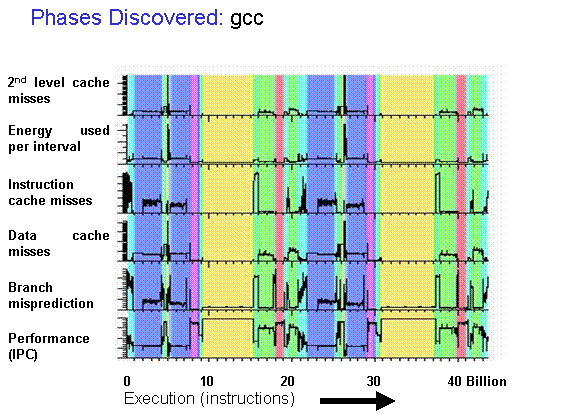
- Program execution traces aren’t random
- They execute the same code again-and-again
- Workload execution traces can be split into phases that exhibit similar μArch behavior
- SimPoint-style representative sampling
- Compute an embedding for each program interval (e.g. blocks of 100M instructions)
- Cluster interval embeddings using k-means
- Choose representative intervals from each cluster as sampling units
SMARTS

- Rigorous statistical sampling enables computation of confidence bounds
- Use random sampling on a full execution trace to derive a population sample
- Central limit theorem provides confidence bounds
- SMARTS-style random sampling
- Pick a large number of samples to take before program execution
- If the sample variance is too high after simulation, then collect more sampling units
- Use CLT to derive a confidence bound for the aggregate performance metric
Functional Warmup
The state from a sampling unit checkpoint is only architectural state. The microarchitectural state of the uArch simulator starts at the reset state!

- We need to seed long-lived uArch state at the beginning of each sampling unit
- This process is called functional warmup
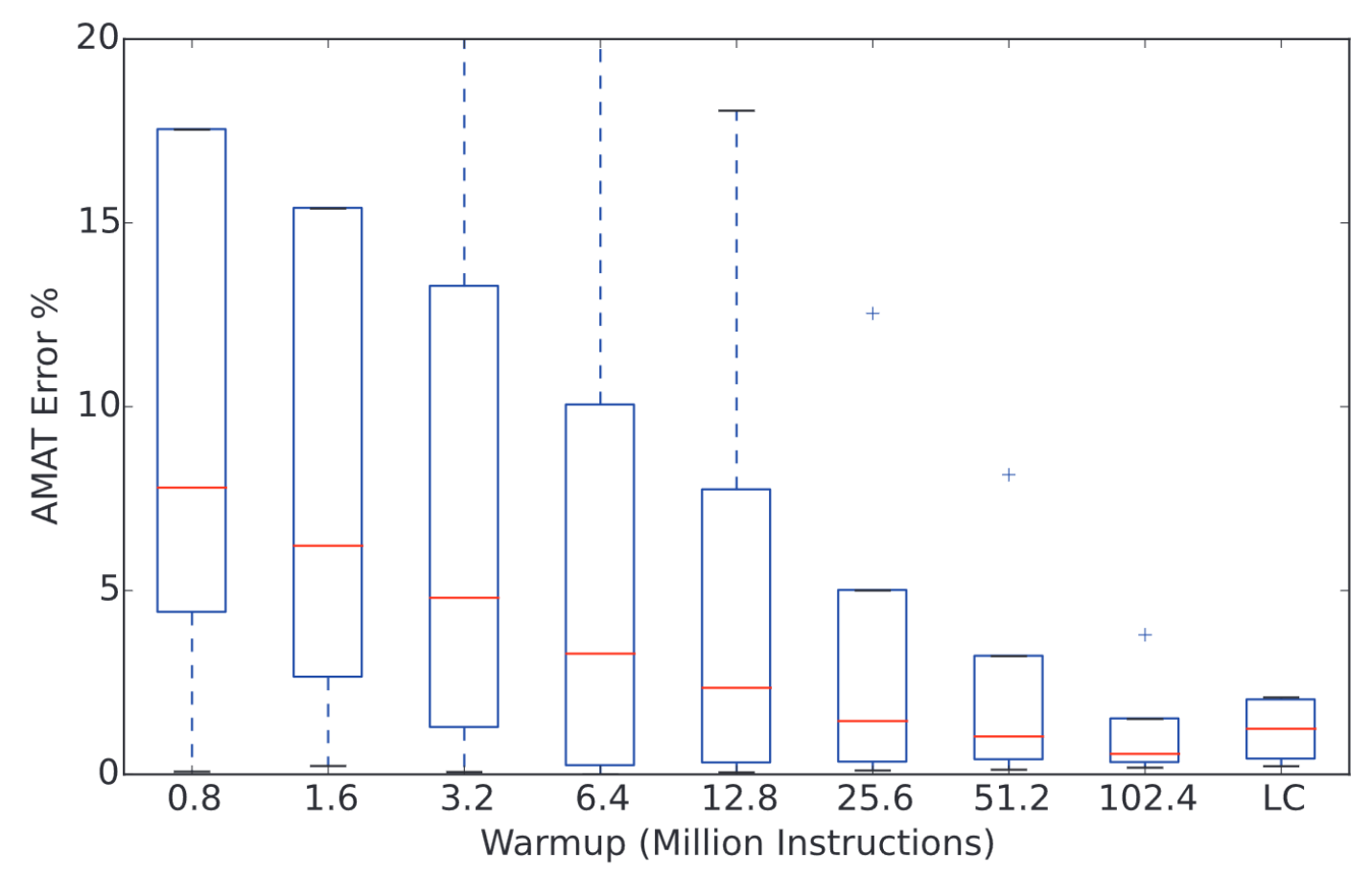
Importance of Functional Warmup
Long-lived microarchitectural state (caches, branch predictors, prefetchers, TLBs) has a substantial impact on the performance of a sampling unit

[1]: Hassani, Sina, et al. "LiveSim: Going live with microarchitecture simulation." HPCA 2016.
[2]: Eeckhout, L., 2008. Sampled processor simulation: A survey. Advances in Computers. Elsevier.
Why RTL-Level Sampled Simulation?

- Eliminate modeling errors
- Remaining errors can be handled via statistical techniques
- No need to correlate performance model and RTL
- Let the RTL serve as the source of truth
- Can produce RTL-level collateral
- Leverage for applications in verification and power modeling
This RTL-first evaluation flow is enabled by highly parameterized RTL generators and SoC design frameworks (e.g. Chipyard).
Implementation of TidalSim v0.1
Sampled RTL simulation with no warmup
Overview of the TidalSim v0.1 Flow

Implementation Details For TidalSim v0.1
- Basic block identification
- BB identification from spike commit log or from static ELF analysis
- Basic block embedding of intervals
- Clustering and checkpointing
- k-means, PCA-based n-clusters
- spike-based checkpoints
- RTL simulation and performance metric extraction
- Custom force-based RTL state injection, out-of-band IPC measurement
- Extrapolation
- Estimate IPC of each interval based on its embedding and distances to RTL-simulated intervals
IPC Trace Prediction: huffbench
- Huffman compression from Embench (huffbench)
N=10000,C=18- Full RTL sim takes 15 minutes, TidalSim runs in 10 seconds
- Large IPC variance

IPC Trace Prediction: wikisort
- Merge sort benchmark from Embench (wikisort)
N=10000,C=18- Full RTL sim takes 15 minutes, TidalSim runs in 10 seconds
- Can capture general trends and time-domain IPC variation

Aggregate IPC Prediction for Embench Suite

Typical IPC error (without functional warmup and with fine time-domain precision of 10k instructions) is < 5%
CoreMark Smoke Test

- NO functional warmup
- 10k instruction intervals, 30 clusters, 2k detailed warmup
- Larger working set means functional warmup is crucial
Functional Warmup of L1d Cache + Early Results
Overall Functional Warmup Flow

- uarch-agnostic cache checkpoints as memory timestamp record (MTR) checkpoints
- Convert MTR checkpoints into concrete cache state with specific cache parameters DRAM contents
- RTL simulation harness injects cache state into L1d tag+data arrays via 2d reg forcing
Memory Timestamp Record

- Construct MTR table from a memory trace, save MTR tables at checkpoint times
- Given a cache with n sets, group block addresses by set index
- Given a cache with k ways, pick the k most recently accessed addresses from each set
- Knowing every resident cache line, fetch the data from the DRAM dump
Results on wikisort

L1d functional warmup brings IPC error from 7% to 2%
Caveats
- Currently all cache lines are marked as dirty, even if read-only
- There seems to be a lingering bug causing unaligned DRAM accesses from L1, still under investigation
- Injection harness is hardcoded for a specific Rocket L1 cache configuration
- Cannot perform L2 injection or handle multiple cores
Next Steps
Multiple Samples per Cluster
- Currently we take the one interval closest to each cluster centroid for RTL simulation
- Problems
- We have no idea how representative the chosen interval is of the cluster
- We have few data points when performing extrapolation
- No simulations are performed for points that are in-between two or more clusters
- Pick both the cluster centroid point and random points within each cluster for simulation
Binary-agnostic Interval Embeddings
- BBVs are tied to a binary
- Can't share embeddings and perf data across simulations
- Embeddings are based on PCs, which is complicated with virtual memory
- There may be different execution patterns of the same code
- We will perform a detailed study of alternative embeddings[1]
- Instruction mix: loads, stores, control, arith, integer, fp
- ILP: in varying window sizes (32, 64, ...)
- Register traffic: avg input operands, number of times a register is consumed, register dependency chains
- Working set: number of unique 32B/4K blocks touched in an interval
- Data stream strides: measure of spatial locality in temporally adjacent memory accesses
- Branch predictability: use an upper-limit branch prediction algorithm (Prediction by Partial Matching)
- Need to balance embedding complexity and accuracy
- Some 'neural' approaches are quite expensive (see: NPS)
[1]: Eeckout, Lieven, et. al. - Exploiting Program Microarchitecture Independent Characteristics and Phase Behavior for Reduced Benchmark Suite Simulation (IISWC 2005)
Streaming Sampled simulation
- Currently, we need multiple passes of spike (2 full runs, 2 log traversals)
- Collect commit log to extract basic blocks
- Re-traverse commit log to build embedding matrix
- After clustering, collect arch checkpoints
- For longer programs, this is expensive and wasteful
- Integrate embedding, clustering, and checkpointing in one pass
- Fixed feature vector size
- Streaming clustering algorithm
- Ability to take checkpoints programatically during spike execution
- Multicore pipelining to mitigate throughput bottlenecks
Leveraging HDLs for TidalSim Methodology
- HW DSE with TidalSim requires an RTL injection harness
- Automatic harness generation using high-level HDLs
- Chisel API to semantically mark arch and uArch state
- FIRRTL pass to generate a state-injecting test harness
class RegFile(n: Int, w: Int, zero: Boolean = false) {
val rf = Mem(n, UInt(w.W))
(0 until n).map { archStateAnnotation(rf(n), Riscv.I.GPR(n)) }
// ...
}
class L1MetadataArray[T <: L1Metadata] extends L1HellaCacheModule()(p) {
// ...
val tag_array = SyncReadMem(nSets, Vec(nWays, UInt(metabits.W)))
(0 until nSets).zip((0 until nWays)).map { case (set, way) =>
uArchStateAnnotation(tag_array.read(set)(way), Uarch.L1.tag(set, way, cacheType=I))
}
}
Conclusion
- We want to enable rapid RTL iteration with performance evaluation and generation of RTL-level collateral
- We need fast, low-startup-latency RTL-level simulation
- We propose TidalSim, a simulation methodology based on sampled RTL simulation
- Everything is open source
- TidalSim (github.com/euphoric-hardware/tidalsim) Forks of spike, chipyard, testchipip + top-level runner
