TidalSim and TraceKit
Explorations of Execution-Driven and Trace-Based Sampled Simulation
Vighnesh Iyer, Bora Nikolic
ATHLETE Update
Monday, August 19th, 2024
TidalSim Recap
- Sampled simulation using RTL simulation
- Short sampling units with functional uArch warmup (a la SMARTs)
- Representative sampling (a la Simpoints)
- Custom uArch (RTL) state injection
- L1 i/d cache functional warmup model to RTL state injection
- Can extend to any long-lived functional unit
- Enables high throughput and accurate simulation of long workloads
- Avoid FPGA iteration latency when doing uArch exploration
- Enables direct iteration on the RTL (not a model)
Why RTL-Level Sampled Simulation?

- In any sampled simulation flow we see time modeling, sampling, and warmup errors
- Direct use of RTL avoids modeling errors from uArch models
- No need to correlate performance model and RTL
- Let the RTL serve as the source of truth
- Produce RTL-level collateral
- Leverage for applications in verification and power modeling
Sampled Simulation Overview
Don't run the full workload in detailed simulation
Run the workload in ISA simulation and pick samples to run in uArch simulation
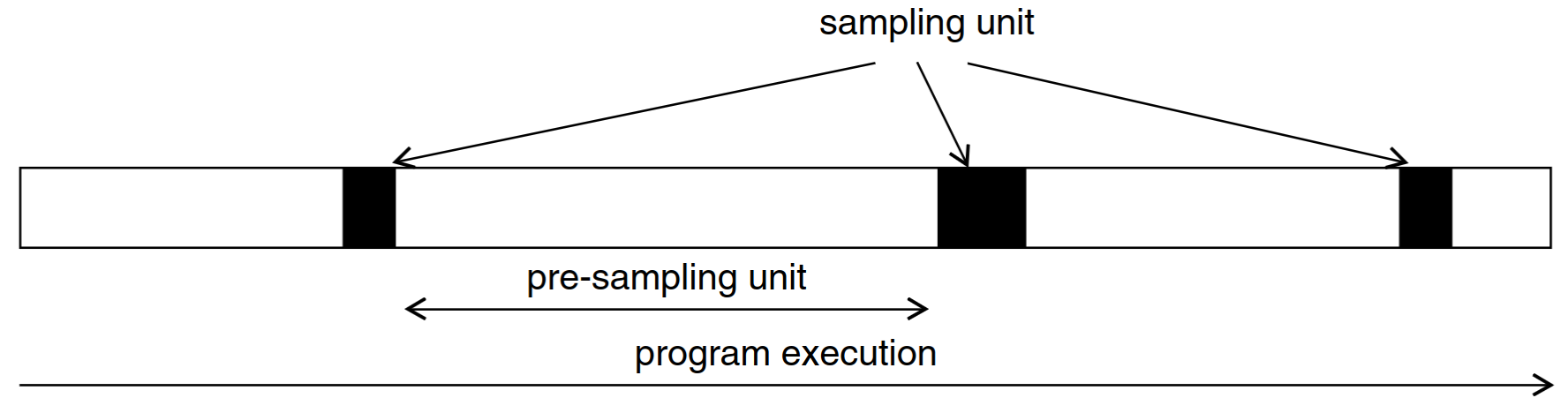
The full workload is represented by a selection of sampling units.
- Sampling unit length: tradeoff runtime and resolution
- Warmup models: which uArch units to initialize
- Clustering and extrapolation: how sampling units should be selected and used for prediction
Functional Warmup
The state from a sampling unit checkpoint is only architectural state. The microarchitectural state of the uArch simulator starts at the reset state!

- We need to seed long-lived uArch state at the beginning of each sampling unit
- This process is called functional warmup
Overview of the TidalSim Flow

Functional Warmup Flow

- Full run of the binary on spike + sampling unit embedding + clustering
- Re-run spike to capture arch checkpoints at the start of sampling units
- Reconstruct L1d cache state for each arch checkpoint
- Inject sampling units into RTL sim and extrapolate
IPC Trace Reconstruction - wikisort
wikisort benchmark from embench, $N = 10000$, $C = 18$, $n_{\text{detailed}} = 2000$

IPC Trace Reconstruction - huffbench
huffbench benchmark from embench, $N = 10000$, $C = 18$, $n_{\text{detailed}} = 2000$

Multithreaded Workload Sampling
Multithreaded Workloads
- HPC (NAS, ScaLAPACK, MPI (Intel/SPEC), Eigen, Cinebench, zstd)
- Compute/memory BW heavy
- Frequent inter-thread communication
- Native use of OS threads
- Insensitive to OS scheduling, stable thread contexts
- Datacenter (nginx, Postgres, Redis, Gitlab)
- IO heavy
- Task-level parallelism, low ILP, inter-thread communication on task init/finish
- OS threads used for blocking IO (network, disk, database, RPC)
- High concurrency, userspace threading (green threads), frequent context switches
Accurate modeling of time is essential for datacenter workloads
Modeling Time in Sampled Simulation

Live sampling (interleaving arch and uArch sim) is required to accurately model time-dependent behaviors.
Prior Work in Multithreaded Sampling
- Specialized ways of selecting sampling units
- TaskPoint[1]: task regions in task-based programming models
- BarrierPoint[2]: synchronization barriers
- LoopPoint[3]: loop-based simulation markers
- Aim to accurately embed behaviors seen in HPC-like workloads
- Time-modeling for throughput oriented applications
- COTSON[4]: model timers and IO devices alongside a functional simulation
- SimFlex[5]: random sampling of throughput-oriented workloads with a timing model
- No modern work attempting to analyze the viability of sampling for modern cloud workloads
[1]: T. Grass, et. al. TaskPoint: Sampled simulation of task-based programs. 2016 ISPASS
[2]: T. E. Carlson, et. al., BarrierPoint: Sampled simulation of multi-threaded applications. 2014 ISPASS
[3]: A. Sabu, et. al., LoopPoint: Checkpoint-driven Sampled Simulation for Multi-threaded Applications. 2022 HPCA
[4]: E. Argollo, et. al. COTSon: infrastructure for full system simulation. SIGOPS 2009
[5]: T. F. Wenisch, et. al. SimFlex: Statistical Sampling of Computer System Simulation. IEEE Micro 2006
Trace-Oriented Sampling

- Remove execution-driven simulation from the picture
- Evaluate sampling error alone from the embedding strategy
- Compare representative vs random sampling
Multithreaded Embeddings

- Aggregated embedding
- Capture SoC-level effects (cache pollution, inter-thread communication)
- Higher dimensionality, clustering might suffer
- Per-core embedding
- Doesn't capture interactions between cores
Tracing @ Google
Tracing Technologies
- DynamoRIO
- Abstraction over low-level tracing APIs (e.g. Intel PIN / PT)
- Dynamic binary instrumentation tool
- Offline analysis of (PC + memory access) traces
- DynamioRIO is used to trace server applications running in sandboxed setups with artificial traffic injection
- Large (~10-30x) application perturbation with full tracing enabled
DynamoRIO Traces
$ bin64/drrun -t drmemtrace -tool view -indir drmemtrace.*.dir -sim_refs 20
Output format:
record instr tid record details
------------------------------------------------------------
1 0: 3256418 marker: version 6
2 0: 3256418 marker: filetype 0x240
3 0: 3256418 marker: cache line size 64
4 0: 3256418 marker: chunk instruction count 1024
5 0: 3256418 marker: page size 4096
6 0: 3256418 marker: timestamp 13312410768080478
7 0: 3256418 marker: tid 3256418 on core 7
8 1: 3256418 ifetch 3 byte(s) @ 0x00007fc205a61940 48 89 e7 mov %rsp, %rdi
9 2: 3256418 ifetch 5 byte(s) @ 0x00007fc205a61943 e8 b8 0c 00 00 call $0x00007fc205a62600
10 2: 3256418 write 8 byte(s) @ 0x00007fff9a9e3528 by PC 0x00007fc205a61943
11 3: 3256418 ifetch 1 byte(s) @ 0x00007fc205a62600 55 push %rbp
12 3: 3256418 write 8 byte(s) @ 0x00007fff9a9e3520 by PC 0x00007fc205a62600
13 4: 3256418 ifetch 3 byte(s) @ 0x00007fc205a62601 48 89 e5 mov %rsp, %rbp
14 5: 3256418 ifetch 2 byte(s) @ 0x00007fc205a62604 41 57 push %r15
15 5: 3256418 write 8 byte(s) @ 0x00007fff9a9e3518 by PC 0x00007fc205a62604
16 6: 3256418 ifetch 2 byte(s) @ 0x00007fc205a62606 41 56 push %r14
17 6: 3256418 write 8 byte(s) @ 0x00007fff9a9e3510 by PC 0x00007fc205a62606
18 7: 3256418 ifetch 2 byte(s) @ 0x00007fc205a62608 41 55 push %r13
19 7: 3256418 write 8 byte(s) @ 0x00007fff9a9e3508 by PC 0x00007fc205a62608
20 8: 3256418 ifetch 2 byte(s) @ 0x00007fc205a6260a 41 54 push %r12
- Application-thread-oriented traces
- Captures all userspace fetches, memory accesses, syscalls, control transfers
Published Memtraces
- Google has published traces for 4 workloads
- Some information is stripped / degraded
- Instruction encodings / source binary / inst dependencies
- Syscalls and syscall numbers
- Timestamps (limited availability and accuracy)
- Some information is unavailable due to limitations in DynamoRIO
- IO activity and when earliest thread resumption is possible
- Kernel space activity
- Inter-thread dependencies / communication
Trace-Driven Sampling Investigation
We wish to answer some questions
- What embedding strategy (core-oriented vs SoC-level) works well for Google traces?
- How do we extract meaningful metrics that we can predict from the trace?
- IPC is iffy due to timestamp granularity (10s of us)
- Cache/BP statistics from PMU are unavailable, but reconstructible to some degree
- How stable are the chosen simpoints under varying scheduling behaviors?
The TraceKit Framework
TraceKit Overview

- Unify trace-level analysis for DR and Berkeley simulation flows
- Lightweight abstraction over ISAs (x86, ARM, RISC-V)
- Evolving this framework for live sampled simulation using RTL sim
The "Scheduler"

- To cope with differences in the number of modeled cores vs cores used in the captured trace
- Can force more aggressive thread interleaving and idle time hole-filling with scheduler-driven preemption and mounting
Limitations
- Traces are fixed! uArch changes can't be incorporated without recapturing.
- uArch changes that impact time-dependent behavior can't be modeled
However, we can evaluate sampling techniques (assuming perfect detailed simulation)
Experiments
- Investigating different embedding strategies
- Basic block vectors
- Instruction mix: loads, stores, control, arith, integer, fp
- ILP: in varying window sizes (32, 64, ...)
- Register traffic: avg input operands, register consumption, register dependency chains
- Working set: number of unique 32B/4K blocks touched in an interval
- Data stream strides: measure of spatial locality in temporal memory accesses
- Branch predictability: use an upper-limit branch prediction algorithm
- Implementation of trace analysis framework over published and internal Google DR traces
- Comparing accuracy of trace-based scheduler vs execution-driven scheduler changes
Questions
Things I'd Like to Know
- What type of performance models are used (trace-driven vs execution-based)?
- What approaches to sampling are used?
- Trace-based sampling
- Multithreaded sampling
- Post-silicon tracing
- Virtual memory handling / ASLR
- Context switches / OS activity
- BW requirements per hardware thread
- External devices
- DMAs / Timers
- HW events in trace / time resolution
- Dynamic on/off
- Any SW instrumentation required? How much analysis is done host-side vs on-chip?
- Boundary IO capture
- How to model time-dependent behavior given a fixed trace?
Conclusion
- Tidalsim provides fast, accurate, low-latency RTL-sim-based sampled simulation
- Ongoing work to leverage Google workload traces for sampling investigation
- TraceKit is a unified trace analysis framework that will be merged with Tidalsim for a multicore live sampling flow
Extra Slides
Existing Sampling Techniques
SimPoint

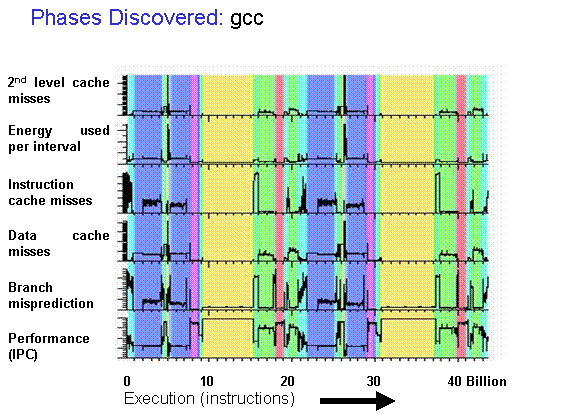
- Workloads can be split into phases that exhibit similar μArch behavior
- SimPoint-style representative sampling
- Compute an embedding for each program interval (e.g. blocks of 100M instructions)
- Cluster interval embeddings using k-means
- Choose representative intervals from each cluster as sampling units
SMARTS

- If we sample from a population, we can estimate the population mean
- SMARTS-style random sampling
- Pick a large number of samples to take before program execution
- If the sample variance is too high after simulation, then collect more sampling units
- Use CLT to derive a confidence bound for the aggregate performance metric
Our proposal: Combine SimPoint-style representative sampling with SMARTS-style small intervals
Implementation Details For TidalSim
- Basic block identification
- BB identification from spike commit log or from static ELF analysis
- Basic block embedding of intervals
- Clustering and checkpointing
- k-means, PCA-based n-clusters
- spike-based checkpoints
- RTL simulation and performance metric extraction
- Custom force-based RTL state injection, out-of-band IPC measurement
- Extrapolation
- Estimate IPC of each interval based on its embedding and distances to RTL-simulated intervals
Memory Timestamp Record

- Construct MTR table from a memory trace, save MTR tables at checkpoint times
- Given a cache with n sets, group block addresses by set index
- Given a cache with k ways, pick the k most recently accessed addresses from each set
- Knowing every resident cache line, fetch the data from the DRAM dump