RTL Sampled Simulation
Vighnesh Iyer, Bora Nikolic
+
Rust-y RISC-V
An Experimental ISS + Baremetal Environment and Benchmark Methodology
Safin Singh, Ansh Maroo, Connor Chang, Pramath Krishna, Vighnesh Iyer, Joonho Whangbo
ATHLETE Quarterly Review
Monday, December 9th, 2024
Overview
- RTL sampled simulation today and its problems
- What does Rust have to do with this?
- An experimental RISC-V instruction set simulator (ISS)
- Architectural description languages + ISS generation + RTL injection
- RISC-V Rust baremetal environment
- Baremetal benchmark generation strategy
- Live sampled simulation leveraging the Rust ISS + benchmarks
What Are We Trying to Solve?
- RTL-first design and evaluation methodology
- Can't afford to build both performance models and implementations
- Build high-level models/simulators and then pipe straight down to implementation
- Iterate directly on the RTL (gives confidence wrt feasibility)
- Extract collateral at the RTL abstraction (e.g. waveforms, power traces)
- RTL simulation techniques have unfavorable tradeoffs
- RTL simulation: fast startup, low throughput
- FPGA-based emulation: slow startup, high throughput
How can we run RTL simulation with fast startup and high throughput?
Our Proposal
- Sampled simulation using software RTL simulation
- Short sampling units with functional uArch warmup (a la SMARTs)
- Representative sampling (a la Simpoints)
- Custom uArch (RTL) state injection
- L1 i/d cache functional warmup model to RTL state injection
- Can extend to any long-lived functional unit
- Enables high throughput and accurate simulation of long workloads
- Avoid FPGA iteration latency when doing uArch exploration
- Enables direct iteration on the RTL (not a model)
Sampled Simulation
Don't run the full workload in RTL simulation
Use an instruction set simulator (ISS) and pick samples to run in RTL simulation
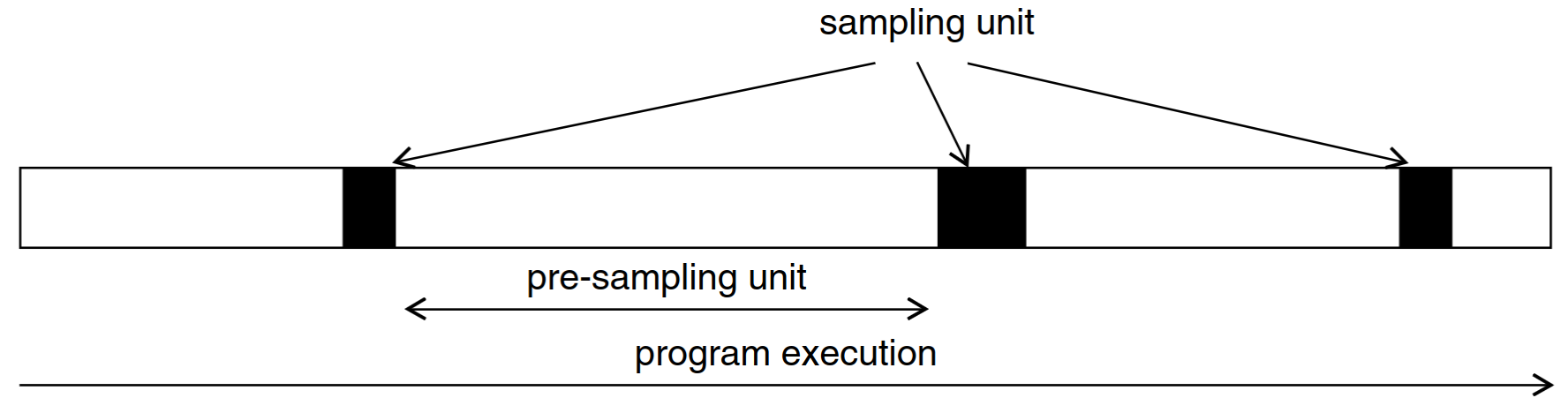
The full workload is represented by a selection of sampling units.
- Sampling unit length: trade off runtime vs resolution
- Sampling unit selection: how sampling units are selected (random vs embedding + clustering) and used for extrapolation
Functional Warmup
A sampling unit is defined by an architectural checkpoint.
The microarchitectural state of the RTL simulation starts at the reset state!

- Solution: seed reconstructed uArch state for each sampling unit
- This process is called functional warmup
RTL Sampled Simulation Flow

Functional Warmup Flow

- Full run of the binary on spike + sampling unit embedding + clustering
- Re-run spike to capture arch checkpoints at the start of sampling units
- Reconstruct L1d cache state for each arch checkpoint
- Inject sampling units into RTL sim and extrapolate
IPC Trace Reconstruction - wikisort
wikisort benchmark from embench, $N = 10000$, $C = 18$, $n_{\text{detailed}} = 2000$

IPC Trace Reconstruction - huffbench
huffbench benchmark from embench, $N = 10000$, $C = 18$, $n_{\text{detailed}} = 2000$

Uninteresting Benchmarks
- It's just doing the same thing over and over again!
- Pretty much all baremetal benchmarks look like this
Problem 1: Embench, Coremark, ... are not interesting enough.
Ad-Hoc Sampled Simulation Methodology

- Some benchmarks look way off, even with warmup
- Certainly a bug in arch state checkpointing, state injection, or uarch injection
Problem 2: No systematic methodology for complete checkpointing and injection.
What Does Rust Have to do With Anything?
What's so Great About Rust?
- Popular selling points
- Borrow checker → safe multithreaded code + memory safety + no memory leaks
- Emitted asm quality similar to C/C++, zero-cost abstractions, quite fast
- No runtime, complete AOT compilation
- But these aren't important to us
- First-class algebraic data types (ADTs) with typeclass derivation
- RISC-V is a first-class target with upstream baremetal support
build.rsfor programmatic code generation- Stdlib that runs baremetal (using
allocandcollections) - A comprehensive package library (crates.io)
- Large number of
no_stdcrates that work baremetal
Heavily used libraries in the wild + baremetal = good
An Experimental RISC-V Instruction Set Simulator (ISS)
Why?
- Spike already exists. What's wrong?
- The 'golden model' of RISC-V
- Extensive set of ISA extensions implemented
- Reasonably fast: 50+ MIPS (much lower when tracing)
- Deficiencies of spike
- Ad-hoc arch state checkpointing
- Non-unified testbench/IO models between spike and Chipyard/FireSim
- Hard to create custom tops (e.g. for live sampled simulation)
Features
This is a purely experimental project
- Support for RV64imfd so far (no privileged ISA)
- Exact diff testing with spike's commit log
- Can run RISC-V ISA tests for supported extensions cleanly
- Leverages riscv-opcodes for instruction encodings
Simple State (De)Serialization
- The ISS is generated after the RTL generator is run
- All SoC state is contained within a single Rust
struct - Typeclass derivation makes it easy to derive serdes on any struct
#[derive(Serialize)]
pub struct Cpu {
pub regs: [u64; 32],
pub pc: u64,
pub csrs: Csrs
}
#[derive(Serialize)]
pub struct System {
pub cpus: Vec<Cpu>,
bus: Bus
}
Disentangling state and update rules seems obvious, but is not so in spike
Codegen-Based ISS
- Swap out the opaque C++ macro system for direct Rust code generation
- Programatically read yaml files in riscv-opcodes and generate Rust strings for instruction decoding, immediate extraction, and the main switch table
- It's just code! No restrictions
- Can also generate code for CSRs with semantic bitfields (this is done manually in spike)
- The device tree from a Chipyard generator is an input into the ISS generation
- The goal is exact SoC modeling
Big Problems
- How can anyone trust a new ISS is precisely emulating the RISC-V spec?
- How can we make the ISS performant?
- How can we exactly model an SoC generated from Chipyard? We can't build a point-design ISS.
Architectural Description Languages (ADLs)
ADLs Broadly
- Formal definition of arch state and update rules at the ISA-level
- Instruction and state encodings
- Execution semantics
- State update rules
- Methods to resolve ambiguities in a spec
- At uArch defition time (e.g. handling of misaligned memory loads/stores, FP exceptions, unimplemented CSR access handling)
- At uArch runtime (e.g. interrupt handling)
Existing Work
- spike is considered a 'golden model', but it isn't a spec in itself
- Undefined behaviors are concretized
- sail-riscv is the official 'formal model' for RISC-V
- Custom DSL (Sail) for specifying execution semantics
- Primarily intended for formal methods (although ISS generators exist - Pydrofoil)
- Others in-the-wild: Vienna ADL, Codasip's CodAL, Qualcomm's riscv-unified-db
- Each one creates a new DSL for describing state, encodings, and update rules
- Instruction-Level Abstraction (ILA)
- C++ eDSL for describing state + update rules
- C++ framework that describes allowable behaviors + bindings to a Verilog implementation
- Designed for accelerator specification
- ARM's Architecture Specification Language (explainer blog post)
- A custom DSL for encoding the formal semantics of the ARM ISA, used mostly for bug hunting against Verilog implementations
Leveraging Chisel
ADLs don't need a new language! It's hardware after all.
- Use Scala/Chisel (with some augmentation) for state, encoding, update rules
- But an ADL doesn't merely describe a single-cycle processor
- Formalize the notion of SoC components (cores, interrupt controllers, IO devices, host tethers, etc.) and how they interact with each other
- Define exactly when architectural state advances
- Specify undefined behaviors and how they should be concretized for modeling a given implementation
- WIP: A Chisel-based ADL embedded in Scala
Generating an ISS from an ADL
- If an ADL simply described a single-cycle SoC, then isn't RTL simulation sufficient?
- Naively doing this will produce a low throughput ISS (e.g. the default C backend of sail)
- Leveraging DBT gives better performance (e.g. Pydrofoil's use of PyPy)
- Key feature: user control over the compilation of an ADL
- Separate the execution semantics of the ADL from codegen optimizations
- Memory block element (scratchpad, cache bank, DRAM) → implementation as a fixed length array, a resizable vector, as a paged hash table, ...
- Naive serial instruction decode, page table translations → implementation with a cache + automatic flushing before state serialization
- "Halide for ISS generation"
RISC-V Baremetal Environment + Benchmarks
Why Baremetal?
- Easy to run in execution driven simulation (RTL simulation)
- Better likelihood of successful arch state transfer
- Focus on common-case userspace code
- But, baremetal programs of course cannot:
- Run kernel code and stress the privileged ISA
- Perform userspace/kernel interactions and witness cache pollution
- Witness preemptive multithreading
Baremetal Rust Programs
- Leverage upstream rust-embedded support
riscv-rt:crt.S,panic!handlers, interrupt handlers- Pre-built hooks for SoC-specific handlers (e.g. using HTIF for host proxying of syscalls)
memory.x: defines the accessible raw address space + program segment mappingtarget = "riscv64gc-unknown-none-elf": that's all it takes to pull in a cross compiler!- Include and use any
no_stddependency with a custom allocator - Build baremetal projects with
cargo buildlike any other Rust project!
- Github
- Implementation of target-side HTIF
- 1:1 port of some benchmarks from
riscv-tests/benchmarks - WIP: semantic port of embench
- Very little code → lots of value
Leveraging no_std Crates
- There are many
no_stdcrates on crates.io that are very popular- Data structures: stdlib, hashbrown, btrees, bigint, petgraph, yada
- Strings: regex, nom
- (De)Serialization: serde, json, yaml, bincode
- Compilers/JIT: cranelift, wasmtime, revm-interpreter
- Hashing / crypto: hmac, aes, rsa, rustls
- Numerics: nalgebra, faer-rs, rust-num, ndarray
- Unlike any other language / environment out there, these crates are easy to use baremetal out-of-the-box
The missing piece: stimulus!
- Caveat: some of these crates have their own benchmarks, which can be used
Extracting Stimuli from Applications
- Tiers of crates
- Base libraries (e.g. data structures)
- Application-level libraries (e.g. HTTP servers)
- Deployed applications (e.g. ripgrep, Alacritty, Servo, Meilisearch)
- Run real applications to derive library-level stimulus
- We can instrument any crate with function argument capturing
- Cargo always compiles from source → adding patched versions of dependencies is easy
A path towards representative, high quality baremetal benchmarks
Conclusion

All these components tie into a robust sampled simulation flow.
Extra Slides
Existing Sampling Techniques
SimPoint

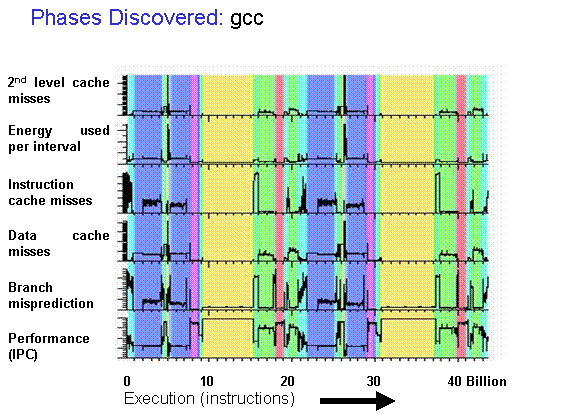
- Workloads can be split into phases that exhibit similar μArch behavior
- SimPoint-style representative sampling
- Compute an embedding for each program interval (e.g. blocks of 100M instructions)
- Cluster interval embeddings using k-means
- Choose representative intervals from each cluster as sampling units
SMARTS

- If we sample from a population, we can estimate the population mean
- SMARTS-style random sampling
- Pick a large number of samples to take before program execution
- If the sample variance is too high after simulation, then collect more sampling units
- Use CLT to derive a confidence bound for the aggregate performance metric
Our proposal: Combine SimPoint-style representative sampling with SMARTS-style small intervals
Implementation Details For TidalSim
- Basic block identification
- BB identification from spike commit log or from static ELF analysis
- Basic block embedding of intervals
- Clustering and checkpointing
- k-means, PCA-based n-clusters
- spike-based checkpoints
- RTL simulation and performance metric extraction
- Custom force-based RTL state injection, out-of-band IPC measurement
- Extrapolation
- Estimate IPC of each interval based on its embedding and distances to RTL-simulated intervals
Memory Timestamp Record

- Construct MTR table from a memory trace, save MTR tables at checkpoint times
- Given a cache with n sets, group block addresses by set index
- Given a cache with k ways, pick the k most recently accessed addresses from each set
- Knowing every resident cache line, fetch the data from the DRAM dump
Overview

- Tidalsim provides fast, accurate, low-latency RTL-sim-based sampled simulation
- Ongoing work to leverage Google workload traces for sampling investigation
- TraceKit is a unified trace analysis framework that will be merged with Tidalsim for a multicore live sampling flow